

Infrastructure: Node.js / Java on Google Kubernetes Engine (GKE)
With a unique positioning in a fast-growing market, the social platform and Moj, their Short Video app, experienced exponential growth in a short period of time.
ShareChat uses custom machine learning algorithms to analyze real-time data in different languages and recommends personalized content to the users based on their likes and dislikes.
The applications (ShareChat and Moj) experience a throughput of 200,000 requests per second (RPS), that’s nearly 17 billion requests a day. The social network analyzes 70 terabytes of data daily to enrich customer experience and business performance with deep insights. ShareChat’s applications are deployed and scaled based on Google Kubernetes Engine, spread across more than 50 clusters with over 200,000 cores deployed.
ShareChat experienced rapid growth which led to inefficient orchestrating, overprovisioning and underutilization. Although they were using automatic tools for instance size management, they were doing hands-on tuning, applying recommendations one by one which was exhausting resources and manpower. This did not solve the problem of Kubernetes overprovisioning which continued to grow rapidly and, with such a large scale of clusters, these manual processes became untenable.
ShareChat saw Granulate as a natural choice to supercharge their optimization and cost reduction efforts due to the following qualities:
Orchestration - With the agent orchestrating Kubernetes resources to fit the actual usage and Granulate’s unique autoscaling capabilities, ShareChat was able to autonomously rightsize their GKE workloads to avoid both overprovisioning and under-utilization.
This capacity management solution also allowed them to scale both vertically and with HPA simultaneously, with none of the typical, wasteful limitations. After applying a single deployment YAML, ShareChat was able to automatically apply HPA, CPU and memory recommendations, allowing them to scale their Kubernetes pods, workloads and nodes.
Optimization - Employing Granulate’s runtime optimization to their Node.js and Java workloads for more efficient use of CPU and memory resources.
Customization - The DevOps team at ShareChat required full visibility of orchestration activities and the ability to determine headroom buffers according to their needs.
Integration With All CSPs - ShareChat teams were able to continue operating with the same processes, using the existing tools on GCP.
Fully Automated - No R&D efforts, and no manual changes.
Improved Stability & Capacity - Granulate unique’s approach reduced CPU utilization and lower latency, providing not only significant cost reduction, but also improved capacity and better stability.
In order to achieve Proof of Concept, ShareChat initially deployed Granulate on 12 of their most mission critical services. Each service is deployed on a different GKE cluster and consists of thousands of pods, handling tens of thousands of requests with strict SLAs.
ShareChat’s custom-built optimizations were ready to be activated after a short 14 day learning phase. During this period, the operating system’s resource usage patterns and dataflow were analyzed to identify bottlenecks and prioritization opportunities.
Upon activation, ShareChat witnessed drastic performance improvement.
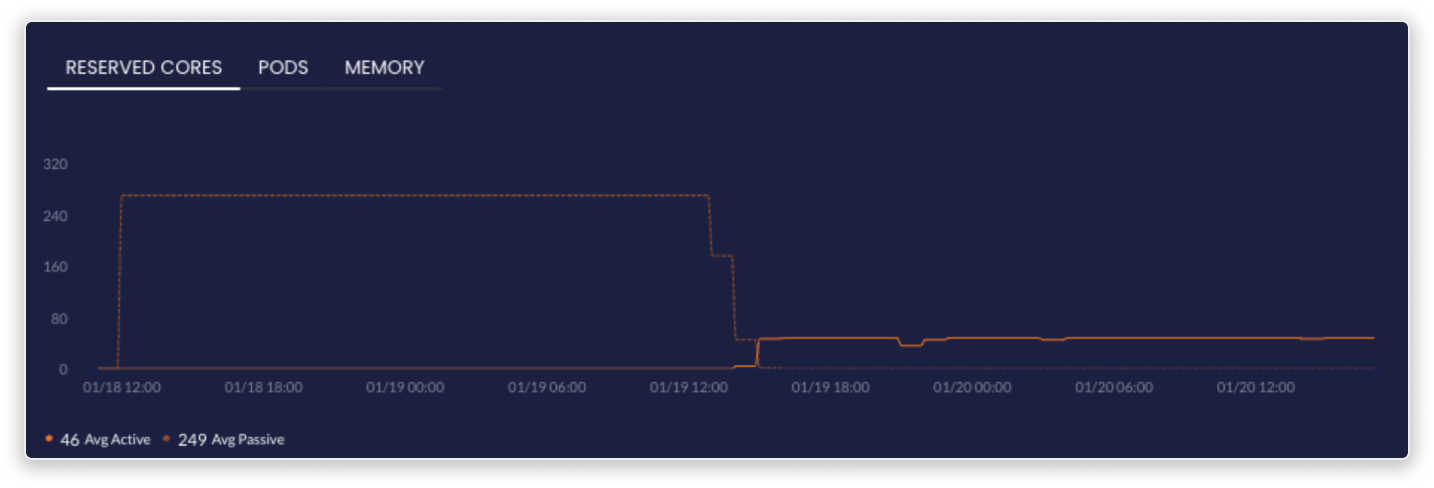
Their CPU utilization and response time were reduced by up to 25% across all optimized services, leading to fewer cores being needed to run the same amount of applications at improved performance.
Due to these promising results, the agent is now deployed across 50 Kubernetes clusters to scale out orchestration even further. Between the orchestration and optimization activities, there was no need for manual work from their R&D team and they saw 20% cost reduction on most clusters.
Social Media
HQ: Bangalore, India
ShareChat (Mohalla Tech Pvt Ltd) is India’s largest homegrown social media company, with 400+ million monthly active users across all its platforms and languages.
Users have multiple options to express themselves through audio
chat rooms, photo & video posts, status updates, microblogging, blogging and direct messaging, allowing regional audiences to connect with like-minded users and communities.
