
Amazon EMR (formerly Amazon Elastic MapReduce) is an AWS managed platform you can leverage to run big data frameworks. It allows you to run Apache Spark and Apache Hadoop, process massive amounts of data, and perform analytics.
Amazon EMR lets you leverage a group of Amazon Elastic Compute Cloud (EC2) instances as a cluster for rapid processing and analysis. Each EC2 instance in a cluster is called a node, and different node types serve diverse roles.
This is part of a series of articles about AWS EMR.
In this article:
- Understanding Clusters and Nodes
- Viewing EMR Cluster Status and Details
- Scaling EMR Cluster Resources
- What Instance Type Should You Use for the EMR Cluster?
Understanding Clusters and Nodes
In AWS EMR, a cluster is a collection of nodes.
The core component of the cluster is the master node. It runs software components that help coordinate the distribution of data and tasks among the various cluster nodes for processing. It also monitors the cluster’s health and tracks the status of tasks. Each cluster has a master node. You can create a single-node cluster with a master node only.

The master node controls multiple core nodes, which use software components for running tasks and storing data in the cluster’s Hadoop Distributed File System (HDFS). A cluster must have one or more core nodes.
Lastly, there are task nodes – these include software components that can only run tasks. They cannot store data in HDFS. In AWS EMR, task nodes are optional.
Here is a diagram visualizing a cluster that includes four core nodes and one master node:
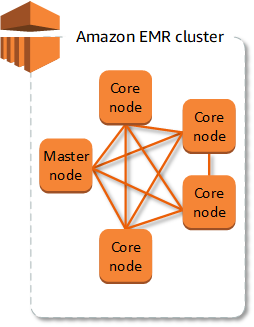
Image Source: AWS
Options for Running Amazon EMR Clusters
Amazon EMR lets you specify the work your cluster needs to perform. Here are the main options:
- When creating a cluster, specify functions as steps that encompass the entire work definition.
- Build a long-running cluster using the Amazon EMR console, API, or CLI to submit steps with one or multiple jobs.
- Create a cluster using SSH to maintain a connection with the master node and other nodes. Next, use the installed applications’ interfaces to perform tasks and submit scripted or interactive queries.
Additionally, you can specify these requirements:
- A region to run your cluster.
- Where and how the cluster stores data.
- How the cluster outputs results.
- Choose between Local Zones and Outposts.
- Choose between long-running or transient clusters.
- Specify the software the cluster runs.
- Determine hardware and networking options to optimize the application’s costs, availability, and performance.
You can quickly create clusters for simple tasks and testing or evaluation purposes using the Create Cluster—Quick Options page in the Amazon EMR console. This option includes default values for configurations like cluster software, security, and networking.
Viewing EMR Cluster Status and Details
After creating an EMR cluster, you can monitor its health, get detailed runtime information, and see any errors that have occurred (this data persists even after you shut down the cluster). Amazon EMR retains metadata for a terminated cluster for two months.
When reviewing historical data, you cannot delete a cluster from the cluster history. However, you can use filters in the AWS Management Console, or the list-clusters command option in the AWS CLI, to view only the clusters you are interested in.
The EMR console offers a cluster list that shows all the clusters in your account and the selected AWS Region, including those that have been terminated. The list displays information such as name and ID for each cluster, status, creation time, total time the cluster has been running, and fully qualified instance hours for every EC2 instance in the cluster.
You can use this list as a starting point to monitor cluster health, drilling down to get more data about each cluster to enable troubleshooting and analysis.
To view a summary of the cluster information:
In the EMR console, in the clusters list, find the cluster you need. In the Name column, next to the cluster’s link, click the down arrow.
The cluster row expands to show details about the cluster, including bootstrap actions, hardware, and steps. This section has links you can use to get more information—for example, you can click the link under a step to access the step log file, the associated JAR, or view tasks and jobs
.

Image Source: AWS
To view the cluster status in detail:
Find the cluster link as described above, and click the link under the cluster name. The cluster details page opens. Each tab lets you view detailed information:
- Summary—basic cluster configuration.
- Application user interfaces—Tez UI application details and persistent YARN timelines off-cluster.
- Monitoring—graphs showing key metrics related to cluster operations.
- Hardware—compute the cluster’s nodes and their details.
- Events—the full event log for the cluster.
- Steps—log files for the steps submitted to your cluster.
- Configurations—customized configuration objects defined for the cluster.
- Bootstrap actions—actions the cluster runs automatically when it launches.

Image Source: AWS
Scaling EMR Cluster Resources
AWS EMR lets you manually adjust the number of available EC2 instances to a cluster or automatically respond to demands. You can use two types of automatic scaling—EMR-managed scaling and custom auto scaling policies. Here are the main differences between these options:
| EMR-managed scaling | Custom auto scaling | |
| Scaling rules and policies | EMR constantly evaluates cluster metrics and makes optimal scaling decisions to manage auto scaling activities. It does not require any policy. | This option requires you to define and manage the cluster’s auto scaling rules and policies, including conditions to trigger scaling, cooldown periods, and evaluation periods. |
| Cluster composition | Can automatically scale instance fleets and instance groups. | Supports only instance groups. |
| Scaling limit configuration | Allows you to configure scaling limits for an entire cluster. | Allows you to configure scaling limits only for each instance group. |
| Frequency of metrics evaluation | Can evaluate metrics every 5-10 seconds. Frequent metrics evaluation enables EMR to make more accurate scaling decisions. | Lets you define the evaluation periods in five-minute increments only. |
| Supported applications | Supports only YARN applications like Spark, Hadoop, Flink, and Hive. | Enables you to choose the supported applications when defining auto scaling rules. |
What Instance Type Should You Use for the EMR Cluster?
You can add EC2 instances to your cluster in different ways depending on the cluster configuration:
- If you have an instance group configuration, you add instances manually to existing instance groups. The instances must be the same type unless you add task instance groups. You can also set up auto scaling in EMR for your instance groups to add and remove instances based on specified Amazon CloudWatch metrics.
- If you have an instance fleet configuration, you can add a single instance fleet and modify the target capacity for Spot and On-Demand instances.
Master nodes don’t usually require EC2 instances with high processing power. Core nodes require EC2 with storage capacity and processing power, while task nodes only need processing power. You can plan cluster instances by running a test cluster using a representative data set and monitoring the node utilization in your cluster.
A typical Amazon EMR cluster has the following:
- A vCPU limit—the total number of on-demand EC2 instances you run on your AWS account in one Region.
- Computational needs—different instance types are better for specific types of processing. You can run clusters with high computational demands on High CPU instances. Clusters with high memory requirements, like memory caches and databases, can run on High RAM instances.
- Capacity needs—different parts of the cluster can require different capacity levels. Start with a few core nodes and scale the task nodes based on the job’s changing capacity requirements.
Optimizing Amazon EMR With Granulate
Granulate excels at operating on Amazon EMR when processing large data sets. Granulate optimizes Yarn on EMR by optimizing resource allocation autonomously and continuously, so that data engineering teams don’t need to repeatedly manually monitor and tune the workload. Granulate also optimizes JVM runtime on EMR workloads.