
Last week we hosted a live session on how businesses can reduce their Total Cost of Ownership (TCO) of Kubernetes. This is an issue that is at the top of mind for DevOps leaders and CTOs, as many have recently incorporated containerized architecture into their application environments in order to enable advanced scalability and hypothetical cost benefits. However, they’ve often found that those costs are rising despite optimization efforts.
In this session, Granulate Solution Engineer Jenny Besedin spoke on the topic with Arun Gupta, Vice President and General Manager for Open Ecosystem at Intel, Governing Board Member at The Linux Foundation and Governing Board Chairperson at Cloud Native Computing Foundation (CNCF). They discussed the fundamental shift from piecemeal to holistic Kubernetes optimization, presented a variety of methods that fit this new approach, and spoke about what the next era of Kubernetes has in store.
Read on for a summary of the session and click here to watch it yourself.
The State of Kubernetes Optimization
In order to understand where Kubernetes optimization is going, we have to understand where it’s been and where it still is for many users.
There are three layers to think about when optimizing your Kubernetes applications:
- Infrastructure Layer – A private cloud or public cloud where the application is running
- Kubernetes Layer – The common compute layer of Kubernetes which could be distribution or upstream for example.
- Application Layer – Where the application is built using Java, Go, Rust or another runtime. This is often packaged as a container and deployed as a bunch of pods.
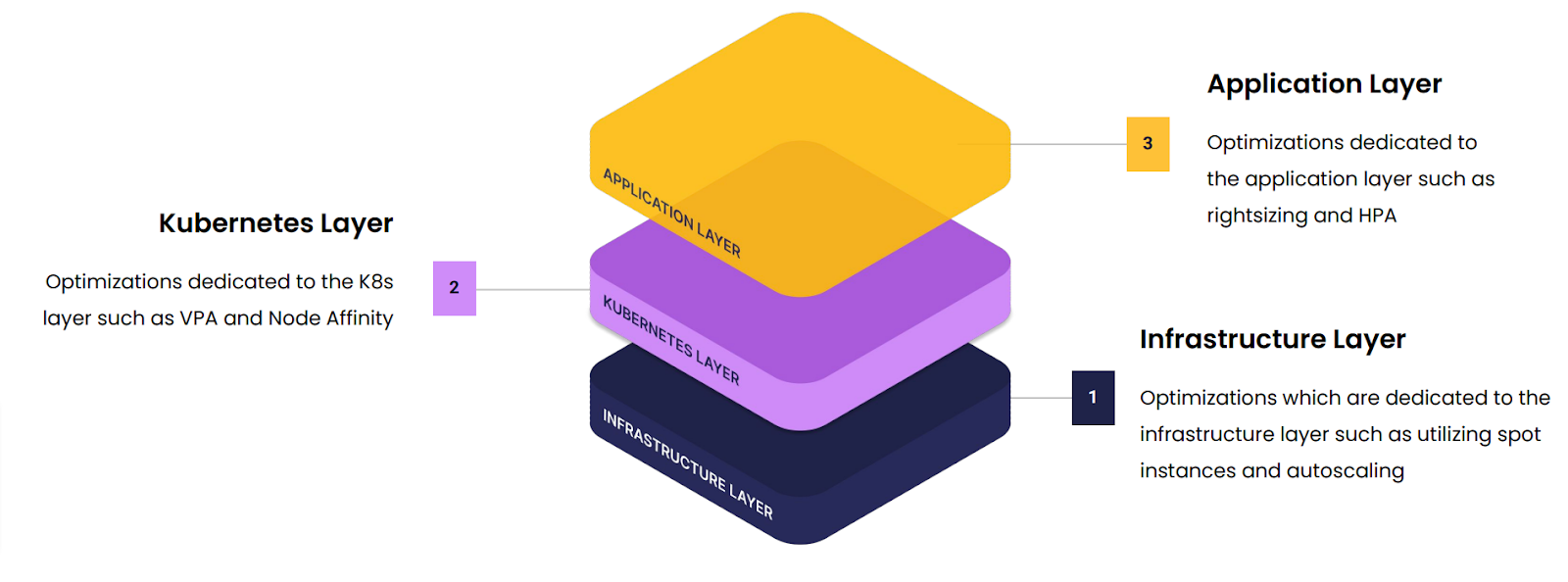
With a more piecemeal approach to optimization, users have been looking at each of these layers, often one at a time, to make their applications run more efficiently. They’d look at the Infrastructure Layer and utilize spot instances and pod autoscaling, then the Kubernetes Layer with CPA and Node Affinity and occasionally the Application Layer as well with rightsizing and HPA.
However, these layers aren’t communicating with each other, so DevOps is only looking at one piece at a time. Furthermore, the optimizations that are being applied on one layer can even harm the efficiency on another layer.
Factors Leading to Piecemeal Optimization
There were a variety of factors that led to piecemeal optimization as the fundamentally fragmented approach to Kubernetes optimization used today.

- Cost reduction prioritization was very different during the early years of Kubernetes adoption. Not too long ago, companies were emphasizing performance, speed and scalability. DevOps often did not have cost KPIs to deliver on. Due to recent macroeconomic conditions, that has changed and cost reduction has become a clear priority.
- Lack of coordinated efforts across multiple teams as each group is concerned with a different layer. With each team siloed, optimization efforts were rarely aligned.
- Partial visibility and monitoring was available, but no full view of all layers that impact performance. Different people were getting visibility into different metrics. For example, one team could be concentrating on latency, while the other is looking at different instance types. This leads to a lack of coordination, a bloated toolstack and faulty measurements for optimization progress.
- Technical complexity only increased as time went on. With this complexity came more tools and technologies, which were distributed across a variety of teams.
- Different approaches to cost reduction were applied, because each team had different tools, skills, expertise and visibility.
Kubernetes Optimizations: Step-by-Step / Layer-by-Layer
There are so many different actions that can be taken to optimize Kubernetes, it’s helpful to look at it step-by-step and layer-by-layer. Many of these motions are manual and hard to align with each other.
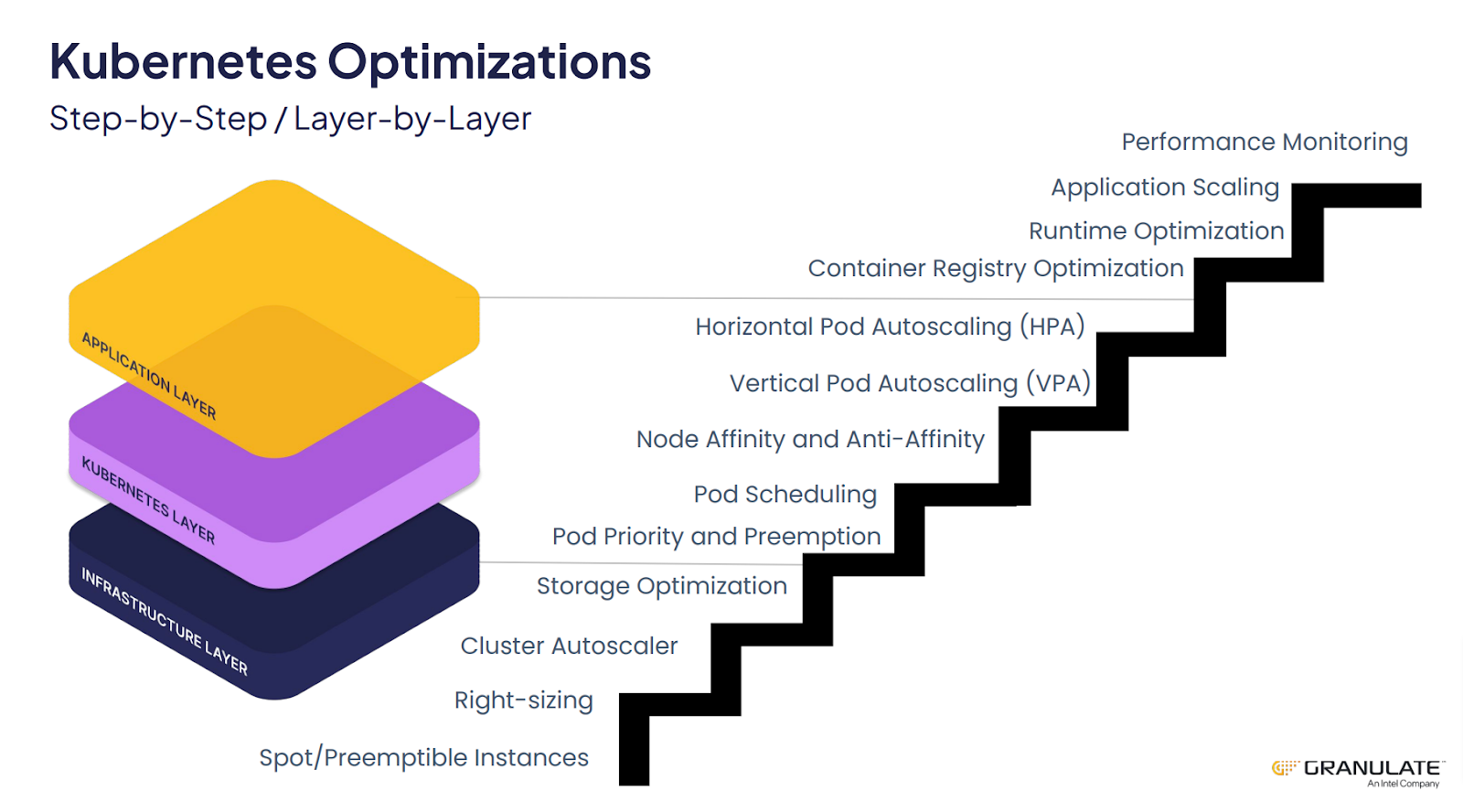
Infrastructure Layer Optimizations
Spot/Preemptible Instances
A popular optimization strategy for the infrastructure layer. Not only do spot instances reduce price, but they also provide significant performance value.
Right-sizing
Analyze your workload requirements and select appropriate node sizes (CPU, memory, storage) to match your application’s needs.
Cluster Autoscaler
Configure auto-scaling mechanisms to automatically adjust the number of nodes based on resource utilization to cope with traffic peaks or overutilization. This is especially challenging for application developers because it requires a unique skill set that they might not have.
Storage Optimization
Choose the right storage solution for your application (e.g. local, network-attached, distributed storage) and configure it for optimal performance.
Kubernetes Layer Optimizations
Pod Priority and Preemption
Assign priorities to pods to indicate their relative importance, allowing the scheduler to make intelligent decisions during resource contention situations and preempt lower priority pods when necessary.
Pod Scheduling
Taints and Tolerations that allow more granular control over the Kubernetes cluster.
Node Affinity and Anti-Affinity
Ensure efficient resource utilization, high availability, and improved performance by controlling pod placement in a Kubernetes cluster.
Vertical Pod Autoscaling (VPA)
Automatically adjusts the resource allocations (CPU and memory) of individual pods based on their actual usage, optimizing resource utilization and improving application performance.
Horizontal Pod Autoscaling (HPA)
Configure HPA to automatically scale the number of pod replicas based on CPU or custom metrics, ensuring optimal resource utilization
Application Layer Optimizations
Runtime Optimization
Optimizing the application itself on the code level by using latest versions and not causing any bottlenecks.
Application Scaling
Design applications to scale horizontally by adding more replicas or leveraging microservices architecture to handle increased load efficiently.
Performance Monitoring
Utilize application-level monitoring tools to identify performance bottlenecks, optimize code, and improve overall application performance.
Challenges With Piecemeal Optimization
As we see from the collections of possible opportunities listed above, tackling Kubernetes optimization with a piecemeal approach can be overwhelming.
The first challenge is maintenance overhead for multiple tools, agents and vendors. If you’re using multiple CSPs, solutions and tools, your costs can become bloated. Moreso, each of these agents and vendors require development attention, taking up precious time and human resources.
The next challenge is missing out on potential cost reduction from other layers. While optimization in one layer might boost performance in another layer, it might also have the opposite effect, negating improvements with conflicting results.
Compatibility is another challenge, considering that optimization efforts across different layers might not even be able to work with each other. They could also become redundant, wasting hours of DevOps work.
The last challenge is requiring multiple iterations instead of a one-stop-shop. If you’re constantly making changes across multiple layers, you don’t know which optimization is being effective.
The Shift to Holistic Optimization
With all of these challenges that come with piecemeal optimization, there has been a recent shift to holistic optimization, strategies that tackle multiple optimization opportunities simultaneously, often with the use of automation.
These strategies have several benefits, including:
- Improved cost efficiency across all layers, making sure that customer SLAs are met while still lowering the cloud bill by using the least amount of VMs, compute and memory.
- Streamlined management and reduced complexity by reducing the number of vendors and avoiding conflicts between disparate solutions and layers.
- Synergy of optimization efforts for maximum impact with each layer building on top of each other.
- Adapting solutions which provide visibility to multiple optimization opportunities. By being deeply transparent, additional opportunities can be discovered.
- Automation driven approach to keep up with changing patterns and usage, enabling optimization no matter the scale.

Granulate as a Holistic Kubernetes Optimization Solution
Granulate is an excellent example of a holistic approach. In the image below you can see the customer journey, beginning with continuous workload rightsizing, followed by capacity optimization, then runtime optimization and back to rightsizing again.
Instead of doing each of these optimizations independently, they are done continuously and autonomously, in order to ensure peak efficiency consistently. This gives users the ability to optimize across different layers simultaneously and constantly.

In order to present this point more clearly, we look into a relevant use case of an unnamed social media company that was using piecemeal optimization methods. They were manually tuning, rightsizing and applying recommendations, while utilizing customized instance types and employing Kubernetes cluster autoscaler.
This strategy was having limited impact, as it did not optimize across all layers at the same time. Once this company incorporated Granulate into their Kubernetes strategy, they were automatically optimizing on all layers with continuous profiling, runtime optimization for application performance and capacity optimization on cloud infrastructure.
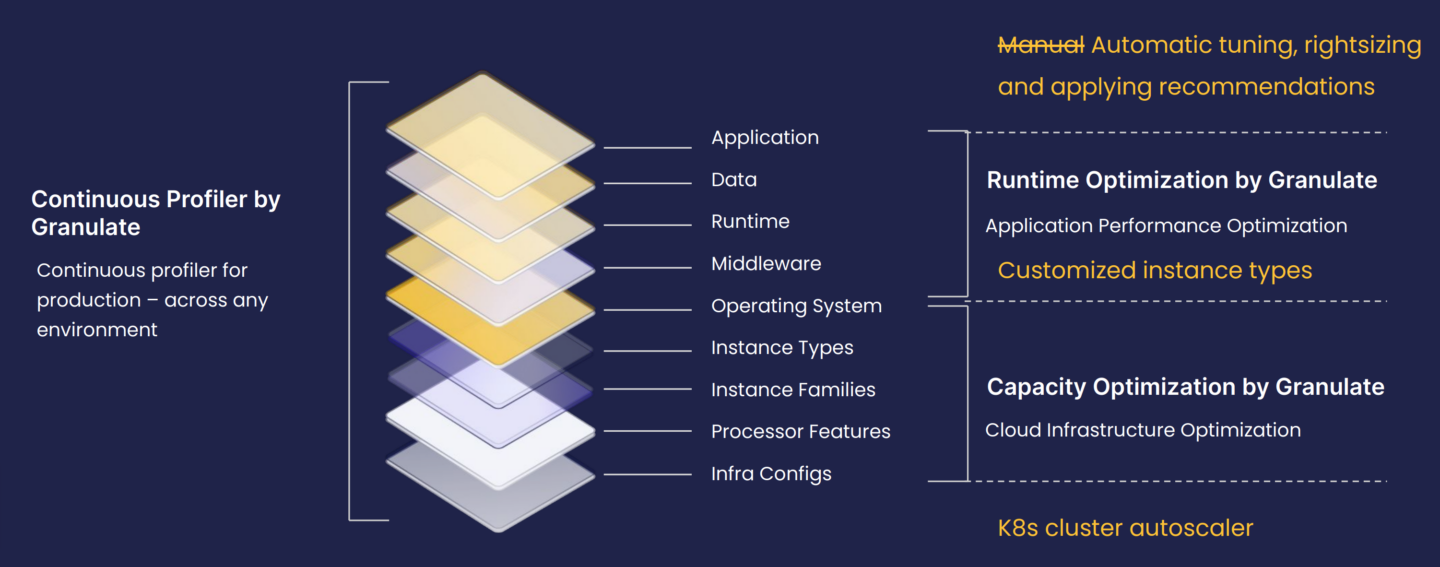
Ultimately, this customer was able to reduce their Kubernetes costs by 20% with Granulate. They supercharged optimization and cost reduction efforts due to the following qualities:
- Orchestration
Kubernetes resources fit actual usage - Optimization
More efficient use of CPU and memory - Customization
Headroom buffers according to needs - Integration
Operating with existing tools on GCP - Automation
No R&D efforts, no manual changes