
Last week we hosted a live session on Best Practices for Embracing EKS for Spark Workloads in collaboration with AWS, for Data Engineers and DevOps that are eager to tap into the benefits of EKS, but are hesitant because of the cost risks associated with containerized environments.
In this session, Intel-Granulate Solution Engineer Avi Rubin spoke on the topic with Kiran Guduguntla, Worldwide GTM Leader at AWS Analytics. They discussed why these migrations are growing in popularity, the cost challenges that come with Spark workloads on containerized environments, and how to mitigate these risks with performance optimization and other techniques like EMR on EKS.
Read on for a summary of the session and click here to watch it yourself.
The Shift of Data Workloads to Kubernetes

Compared to other types of workloads, Big Data is relatively new. The amount of data is growing rapidly and dwarfs that amount of Big Data applications that were around even five or ten years ago.
As the amount of data grows, one of the corresponding trends is that more businesses are choosing to migrate their data workloads onto Kubernetes.
Many of these companies are opting for Amazon Elastic Kubernetes Service (Amazon EKS), a managed Kubernetes service to run Kubernetes in the AWS cloud and on-premises data centers.
To help their customers streamline and accelerate the process of building, deploying and scaling data workloads, which can be a bit challenging, AWS introduced a project called Data on EKS.
Data on EKS (DoEKS) is a tool for building AWS managed and self-managed scalable data platforms on EKS. With DoEKS, customers have access to infrastructure as code templates that were built using Terraform and AWS CDK.
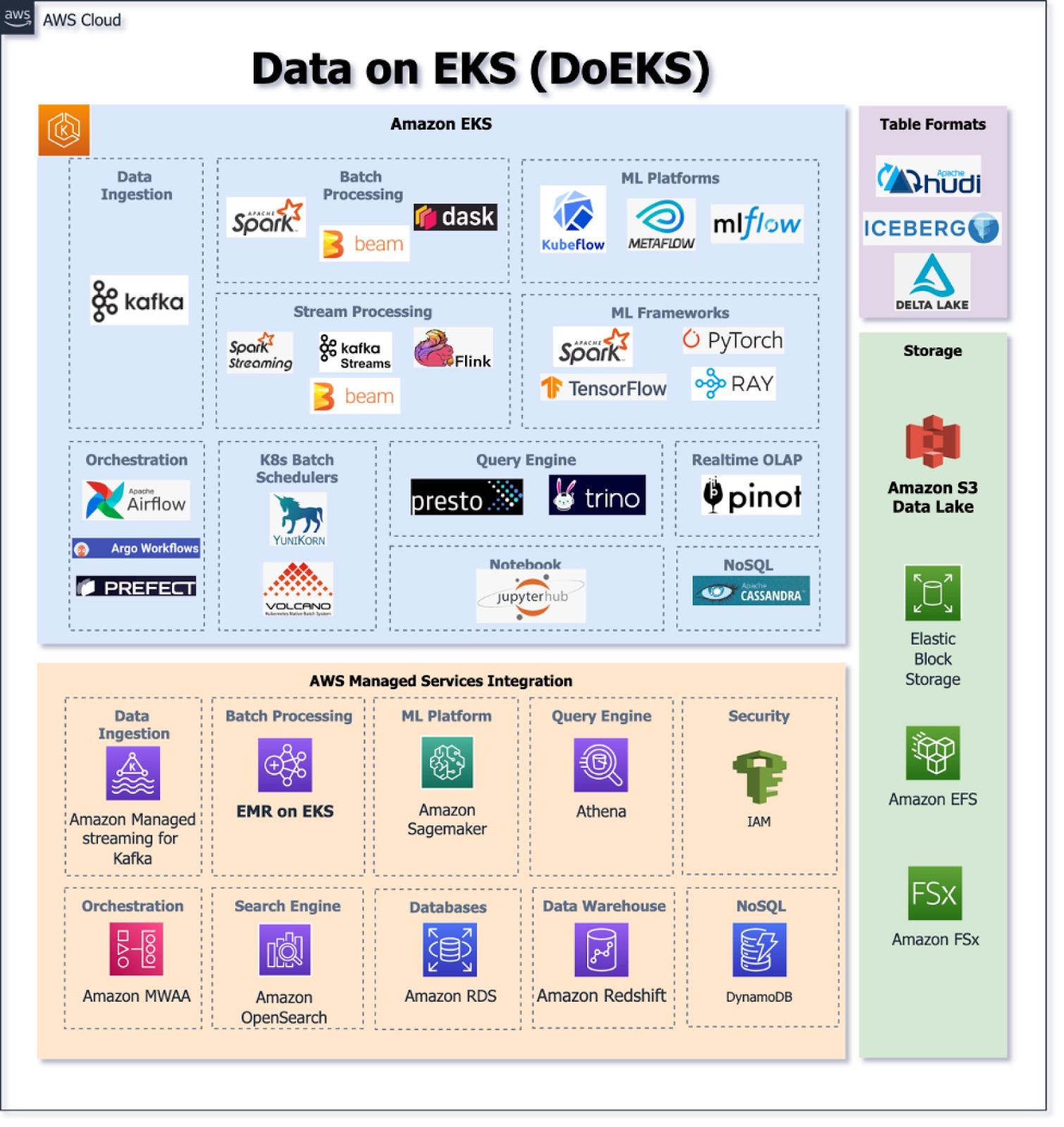
DoEKS users also get:
- Best practices for deploying data solutions on EKS
- Detailed performance benchmark reports
- Hands-on samples for running Apache Spark, machine learning jobs and various other frameworks
- In-depth reference architectures and data blogs
Claroty: Spark on EKS Success Story
Claroty is a cybersecurity company that was experiencing rapid growth leading to increasing cloud costs. The company’s growth was skyrocketing and they were trying to improve the quality of their product, while maintaining the infrastructure. They were dealing with huge environments that were constantly changing and applications running on those environments were evolving as well.
Performance is crucial for the company’s cybersecurity product and applications must be ready to monitor, locate and resolve threats at all times. It is mission critical for them to maintain performance, reliability and stability, because other companies rely on Claroty for their, their most critical needs.
They started trying to limit their growing cloud costs with manual tooling and recommendations, requiring hands-on engineering efforts to identify where the bottlenecks are and resolve those bottlenecks.
Claroty first installed Granulate’s open-source continuous profiler on their EKS cluster. They saw that there was significant potential for optimization, so their DevOps decided to install the Granulate agent to optimize their Apache Spark cluster, which was running on multiple nodes in EKS on AWS.
Less than two weeks after implementing Granulate’s runtime and capacity optimization solutions, Claroty saw impactful performance improvements. They were then able to accelerate their real-time data processing and AI pipeline with better integration of DB and ETL.

After seeing significant value on their largest Spark cluster, which was geographically oriented towards the United States, Claroty expanded to additional regions. These expansions garnered immediate results, requiring no R&D efforts nor the need for the agent to relearn.
These performance results translated into leaner and more efficient use of resources, including a 50% reduction in memory usage and a 15% reduction in CPU utilization. Claroty applied those reductions to improve their bottom line, achieving a 20% reduction in costs and consequently decided to deploy Granulate across the rest of their Big Data clusters.
Why AWS Customers Switch to Containers
Around the world, many AWS customers are containerizing their data solutions, much like Claroty.
Here are four of the main reason why:
- Reduced Risk – Uniform security across environment, maintained with automation
- Operational Efficiency – Reduced operational burden by removing undifferentiated heavy lifting
- Speed – Consistent environment improves developer velocity
- Agility – Automation increases speed and ease of testing and iterating

EMR on EKS is ideal for customers wanting to run analytics workloads on a Kubernetes service and those who only want to use compute capacity from EKS. With EMR on EKS, it is no longer necessary to build more clusters specifically for analytical workloads. Rather, they can run their Spark runtime applications quickly on existing EKS clusters.
This strategy offers more than just convenience. It is also more flexible, allowing customers to run multiple versions of Spark on the same cluster. With this deployment method, teams can stay agile by making quick updates to both applications and the runtime.
Consolidate EMR workloads with other workloads on EKS to:
- Simplify infrastructure management
- Consolidate multiple versions of Spark on same EKS cluster
- Simplify Spark application upgrades
- Add Multi-AZ resiliency by EKS with worker nodes across multiple AZs
Cost Considerations of Containerized Environments
There is always a tradeoff when it comes to taking a new direction and, when it comes to migrating Big Data applications to Kubernetes, that tradeoff is costs.
Here are a few of the main cost concerns when it comes to migrating Spark workloads to EKS.
Overhead
Kubernetes is a managed service with a uniform cost per hour and per cluster. While EKS offers good terms for its customers and EMR on EKS is incredibly cost efficient, that’s still an addition to overhead expenditures.
Wasted Resources
With autoscalers comes the slight risk of over-provisioning on the orchestration layer, whereas non-containerized environments only use resources needed to operate the applications.
Development Efforts
The cost of the work hours and expertise required to effectively operate the more intricate architecture of Kubernetes.
Luckily, there are a handful of solutions for these cost concerns widely available.
Here are three steps to mitigate the cost concerns that are inherent in containerized services:
- Configure the scaling policies appropriately.
- Delegate by using a managed service like EMR on EKS.
- Optimize with an autonomous orchestration tool like Intel-Granulate.
Configure: Optimization Techniques for Data Workloads
Here are a few optimization techniques that you can apply immediately and on your own to start saving on Big Data costs today.
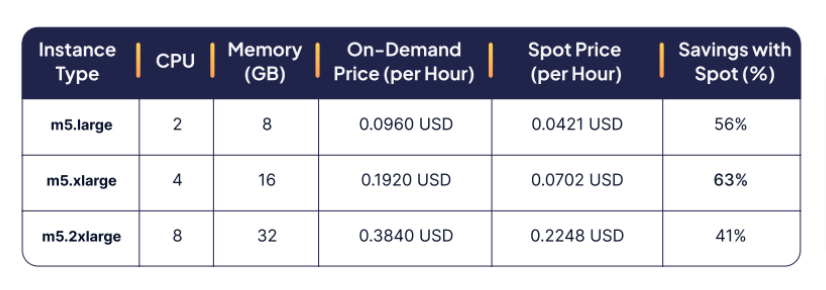
- Right-size EC2 instances: Use the right EC2 instances for your workloads to save costs.
- Use Fargate for stateless workloads: Use AWS Fargate to run stateless workloads, and only use EC2 instances when you need to run stateful workloads.
- Use spot instances for non-production workloads: Use spot instances to save money on non-production workloads that are not critical.
- Enable autoscaling: Use autoscaling to automatically adjust the number of worker nodes based on CPU and memory utilization.
Total savings could be even higher with the help of automation, workers, and autoscaling.
Delegate: Amazon EMR on Amazon EKS
Delegating the undifferentiated heavy lifting to AWS managed services is another excellent method to mitigate costs concerns.
Consolidate infrastructure across organization
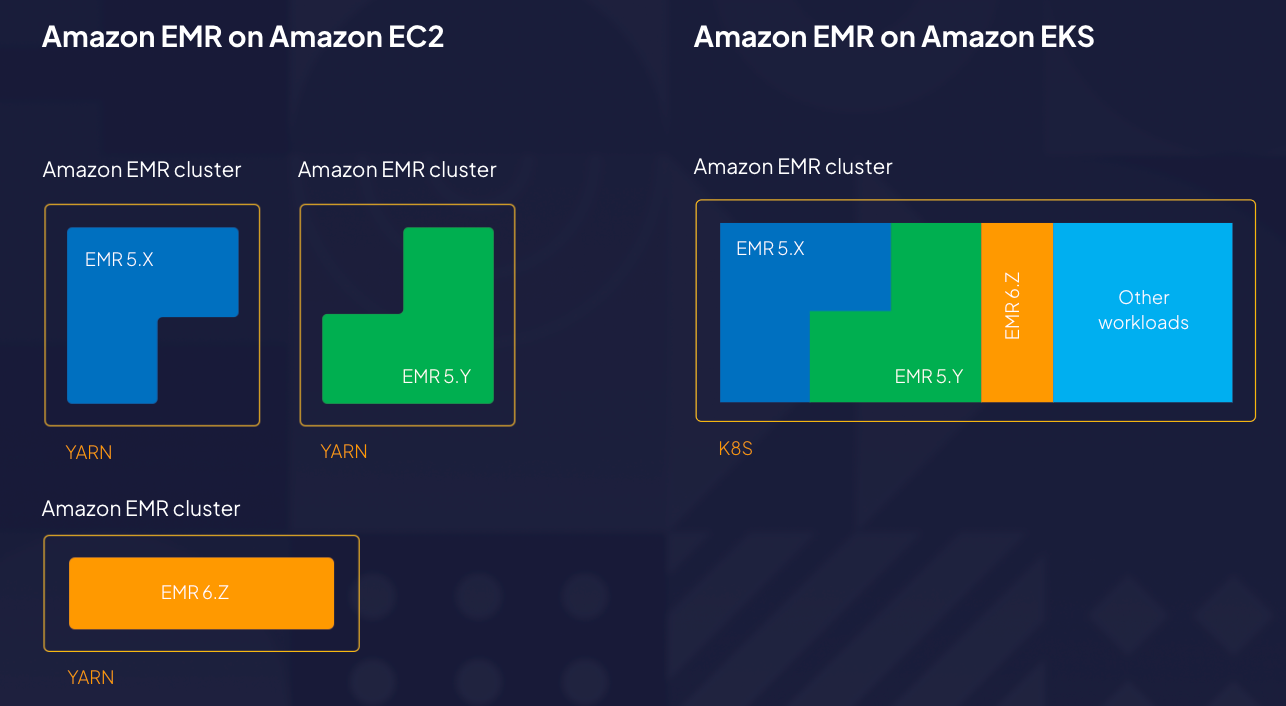
The primary benefit for EMR on EKS is that you can consolidate support work reports with other analytical applications running on EKS, which can help instill very efficient resource utilization.

As this picture displays, all the infrastructure is managed with the EKS, either on EC2 instances or using Fargate for a completely serverless experience. EMR at the center of this picture is a virtual cluster that you can use to submit your Spark jobs.
Usually you’re working with a cluster-centric model, whether it’s Hadoop on-prem or EMR on EC2. But, with EMR on EKS, it becomes a job-centric model, and you can avoid work on the infrastructure because that’s being taken care of by the EKS.
Start jobs quickly, no cluster provisioning delays
If you have transient clusters, sometimes it can take seven to ten minutes for the cluster to come up. That can have an impact on your job runtime and incurred costs. With EMR on EKS, you can start the jobs much faster because the resources are readily available.
Run application on single AZ or across multiple AZs
With EMR on EKS, you can run the application on single Availability Zones or multiple Availability Zones, which can provide enhanced resiliency.
EMR on EKS also offers additional customization by allowing you to manage resource limits by teams and workload, and choose serverless with AWS Fargate on Amazon EKS.
You can see how EMR on EKS compares to EMR on EC2 saves on costs in this image below.
Here are some more benefits of running Spark jobs on EMR on EKS:
- Consolidate multiple analytics workloads on EKS using containers
- Differentiated performance compared to OSS Spark on Kubernetes
- New OSS versions within 30 days of release
- Use serverless containers using AWS Fargate
- Simple Spark-submit like APIs to submit and monitor job process
- Integration with EMR Studio for interactive data science and machine learning workloads
- Simplified Debugging using Spark UI
- Per Job execution role for fine-grained access control
- Use S3 as a Data Lake
- Airflow operators & Step Function integration to run pipelines
- Priced for CPU and memory consumed
- Cross-AZ clusters
Optimize: Autonomously Reduce Costs With Intel-Granulate
Now, let’s assume that your workloads are entirely on EMR on EKS. You’re feeling these advantages and you want to take it a step further by optimizing the environment itself on the actual runtime.
Intel-Granulate empowers AWS users with real-time, continuous workload performance optimization and capacity management, leading to reduced cloud costs. Available in the AWS marketplace, Granulate’s solution operates on the runtime level to optimize workloads and capacity management automatically and continuously without the need for code alterations.

Granulate supports AWS customers by optimizing the most popular compute services including EC2, EKS, ECS and EMR. With Granulate, AWS customers are seeing improvements in their job completion time, throughput, response time, and carbon footprint, while realizing up to 45% cost savings.
Intel-Granulate‘s capacity optimization offering is a powerful Kubernetes tool that uses machine learning algorithms to analyze your application’s performance and automatically optimize your workload. Capacity optimization provides granular control over the CPU and memory resources allocated to each container in your deployment, helping to eliminate unnecessary waste and reduce your computing costs.
Here are some of the key features of Granulate as it pertains to Kubernetes:
- Automatic optimization: Granulate uses machine learning algorithms to optimize your Kubernetes workloads for peak performance and efficiency automatically. It dynamically adjusts the resource allocation for each container in your deployment based on real-time performance data.
- Granular control: With capacity optimization, you have fine control over the CPU and memory resources allocated to each container in your deployment. You can set specific resource limits for each container or let Granulate do it automatically.
- Real-time insights: Granulate’s capacity optimization dashboard provides real-time insights into your application’s performance and resource utilization. You can easily track metrics like CPU and memory usage and view detailed reports on resource consumption and efficiency.
- Cost savings: By automatically optimizing your Kubernetes workloads, capacity optimization can help you save on compute costs. It eliminates unnecessary waste by allocating resources more efficiently and enables you to avoid overspending on excessive computing resources.

Granulate’s optimization solution for Kubernetes is designed to work seamlessly with all major cloud providers, including AWS, GCP, Azure, and OpenShift. By leveraging Granulate’s deep expertise in optimization, you can reduce your compute costs and ensure optimal performance for your Kubernetes workloads.