
What Is Apache Spark?
Apache Spark is an open-source, distributed computing system used for big data processing and analytics. It was developed at the University of California, Berkeley’s AMPLab in 2009 and later became an Apache Software Foundation project in 2013.
Spark provides a unified computing engine that allows developers to write complex, data-intensive applications using a variety of programming languages such as Scala, Java, Python, and R. Spark’s distributed architecture allows it to scale out computations across a cluster of machines, making it well-suited for handling large datasets and high-performance computing.
Spark includes several components, such as Spark Core, which provides the foundation for distributed programming; Spark SQL, which allows developers to work with structured and semi-structured data using SQL queries; Spark Streaming, which enables real-time processing of data streams; and Spark MLlib, which provides machine learning algorithms for data analysis and modeling.
Spark’s popularity has grown rapidly due to its ability to handle a wide range of use cases, from batch processing to real-time streaming and machine learning. It is widely used in industries such as finance, healthcare, telecommunications, and eCommerce, among others.
In this article:
Apache Spark Concepts
Here are some of the fundamental concepts of Apache Spark:
- RDDs (Resilient Distributed Datasets): RDDs are the fundamental data structure in Spark, which represent a fault-tolerant set of elements for parallel processing. RDDs can be created from various data sources, such as Hadoop Distributed File System (HDFS), Apache Cassandra, and Amazon S3.
- Transformations: Transformations are operations that can be applied to RDDs to create a new RDD. Examples of transformations include map, filter, and groupBy. Transformations in Spark are lazy, which means they are not executed immediately, but rather when an action is called.
- Actions: Actions are operations that trigger the execution of transformations and return the result to a driver program or write data to an external storage system. Examples of actions include count, collect, and reduce.
- Spark SQL: Spark SQL is a module in Spark that provides a programming interface to work with structured and semi-structured data. Spark SQL supports SQL queries, DataFrame API, and Dataset API to query and manipulate data.
- Spark Streaming: Spark Streaming is a module in Spark that enables processing of real-time data streams. Spark Streaming processes data streams in small batches, which enables low-latency processing of data streams.
Learn more in our detailed guide to Spark streaming - Machine Learning Library (MLlib): MLlib is a module in Spark that provides a distributed machine learning library for scalable machine learning tasks. MLlib includes algorithms for classification, regression, clustering, and collaborative filtering.
- GraphX: GraphX is a module in Spark that provides a distributed graph processing library for processing large-scale graphs. GraphX includes algorithms for graph processing, such as PageRank and connected components.

Apache Spark: Tutorial and Quick Start
This tutorial is based on the official Spark documentation.
Download and Run Spark
Go to the Spark project’s website and find the Hadoop client libraries on the downloads page. Download the free Hadoop binary and augment the Spark classpath to run with your chosen Hadoop version. Alternatively, download a pre-packaged library for a popular Hadoop version.
Spark can run on Windows or UNIX systems, including any platform with a supported Java version. Ensure Java is installed on your local machine’s system path or Java_home environment.
You can use the ./bin/run-example command in the Spark directory to run an example Scala or Java program:
./bin/run-example SparkPi 10
Another option is to use a modified Scala shell version to run Spark interactively:
./bin/spark-shell --master local[3]
In this script, –master specifies the cluster’s master URL while local[3] allows Spark to run locally with three threads. To run it interactively with Python, use:
./bin/pyspark --master local[3]
Quick Start
Here is a quick guide to get started with Spark.
Interactive Data Analysis
The Spark shell makes it easy to learn how to use the API and analyze data in an interactive manner. The shell is available in Python or Scala and can be run using the ./bin/spark-shell command in the directory. Spark uses Datasets to abstract collections of items – you can create a Dataset from another Dataset or using an HDFS file. For example:
Before executing the following command, copy the License file from the main folder to the bin folder and rename it License.txt
scala> val textFile = spark.read.textFile("License.txt")
To get the values from your Dataset:
scala> textFile.count() // The number of items in the Dataset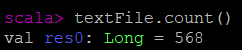
scala> textFile.first() // The first item in the Dataset
You can transform an existing Dataset to create a new one with the following:
scala> val linesWithSpark = textFile.filter(line => line.contains("Apache"))
Operations on the Dataset
You can use Dataset transformations and actions for complex tasks, such as identifying the line with the largest number of words:
scala> textFile.map(line => line.split(" ").size).reduce((a, b) => if (a > b) a else b)
This will create a Dataset by mapping a line to a value, with the reduce operation used to identify the largest word count.
Another option is a MapReduce data , which you can implement with the following:
scala> val wordCounts = textFile.flatMap(line => line.split(" ")).groupByKey(identity).count()
Spark Caching
You can pull Datasets into an in-memory cache that spans the cluster. This is useful for frequently accessed data. Start by marking the Dataset for caching:
Download a sample dataset using the following command:
val usersDF =
spark.read.load("examples/src/main/resources/users.parquet")
scala> usersDF.cache()
scala>usersDF.count()
You can use these functions to cache large Datasets distributed across hundreds of nodes.
Create a Self-Contained Application
You can write self-contained apps with the Spark API. Here is an example of an application in Scala using an sbt configuration file:
/* ExampleApplication.scala */
import org.apache.spark.sql.SparkSession
object ExampleApplication {
def main(args: Array[String]) {
val logFile = "SPARK_LOCATION/README.md"
val spark = SparkSession.builder.appName("Example Application")
.config("spark.master", "local")
.getOrCreate()
val logData = spark.read.textFile(logFile).cache()
val numAs = logData.filter(line => line.contains("a")).count()
val numBs = logData.filter(line => line.contains("b")).count()
println(s"Lines containing a: $numAs, Lines containing b: $numBs")
spark.stop()
}
}
This program will count the number of lines with ‘a’ and ‘b’ in the README file. You can initialize the SparkSession as part of your program by calling the SparkSession.builder to create the SparkSession. Next, specify the app’s name and get a SparkSession instance by calling getOrCreate.
The sbt config file defines Spark as a dependency, specifying the repository it depends on:
name := "Example Project"
version := "1.0"
scalaVersion := "3.18.13"
libraryDependencies += "org.apache.spark" %% "spark-sql" % "3.3.2"
The ExampleApplication.scala and build.sbt should be laid out in a standard directory structure:
$ find .
.
./build.sbt
./src
./src/main
./src/main/scala
./src/main/scala/SimpleApp.scala
Download the SBT tool for building Scala projects (from the official site) and follow the instructions for installation as per your operating system.
In order to build above project, please change directory to folder containing your code and type sbt:

You can execute the application using the run command within SBT:

Other dependency management tools such as Conda and pip can be also used for custom classes or third-party libraries.
Apache Spark Optimization with Granulate
Granulate optimizes Apache Spark on a number of levels. With Granulate, Spark executor dynamic allocation is optimized based on job patterns and predictive idle heuristics. It also autonomously and continuously optimizes JVM runtimes and tunes the Spark infrastructure itself.
Learn more in our detailed guide to apache spark tutorial