
What Is Azure Databricks?
Azure Databricks is an Apache Spark-based analytics platform optimized for the Microsoft Azure cloud services platform. It is provided as a first-party service within the Azure cloud, designed in partnership with Databricks, whose founders were also the creators of Apache Spark. The Azure DataBricks service provides one-click setup, streamlined workflows, and an interactive workspace that enables collaboration between data and business teams.
Azure Databricks can handle all common data and analytics processes—from ETL to exploring data and building AI solutions, all within a single platform. It offers an interactive workspace where data scientists, data engineers, and business analysts can work together to create complex models.
This is part of a series of articles about Databricks optimization.
In this article:
- Key Features of Azure Databricks
- Azure Databricks Pricing
- Databricks Integration with Azure Services
- Setting Up Azure Databricks In Your Own Virtual Network
Key Features of Azure Databricks
1. Native Azure Integration
Azure Databricks is natively integrated with Azure, providing seamless workflows and a unified experience. This integration allows data to be easily ingested from a variety of sources across the Azure ecosystem, including Azure Data Lake Storage, Azure SQL Data Warehouse, and Azure Blob Storage. The native integration also allows for reliable and secure data protection through Azure Active Directory and Azure Private Link.
2. Interactive Workspaces
Interactive workspaces allow data scientists, engineers, and business analysts to collaborate effectively. Through these interactive workspaces, users can write in SQL, Python, R, Scala, and more, all in a single notebook. The workspaces offer visualizations for interpreted data, making it easier to understand and use.

3. Serverless Configuration
Azure Databricks provides serverless configurations, which automatically take care of all the infrastructure complexities. This means that you don’t have to worry about resource management—Azure Databricks simplifies the process by automatically scaling and tuning resources as needed.
4. Real-Time Analytics
With Azure Databricks, you can perform real-time analytics on your data. This feature allows you to process and analyze data as it arrives in real-time. This is especially beneficial for businesses that require immediate insights to make informed decisions.
Azure Databricks Pricing
Azure Databricks pricing is based on a combination of workspace type (Standard or Premium) and the types of virtual machines used in the clusters. The cost is then derived from the number of Databricks Unit (DBU) hours used. A DBU is a unit of processing capability, measured in terms of CPU and memory.
For example, say you choose the Standard workspace type and the D3v2 virtual machine, which costs $0.413 per DBU hour. If your cluster was running for 10 hours, the total cost would be $4.13. If you used a more powerful virtual machine, like the D13v2, which costs $1.10 per DBU hour, the total cost for 10 hours would be $11.00.
Note that the price of Azure Databricks can vary significantly based on the type of workspace (Standard or Premium) and virtual machine chosen. Prices are subject to change.
Learn more in our detailed guide to Azure Databricks pricing
Databricks Integration with Azure Services
Azure Databricks offers seamless integration with many Azure services. The main ones are detailed below.
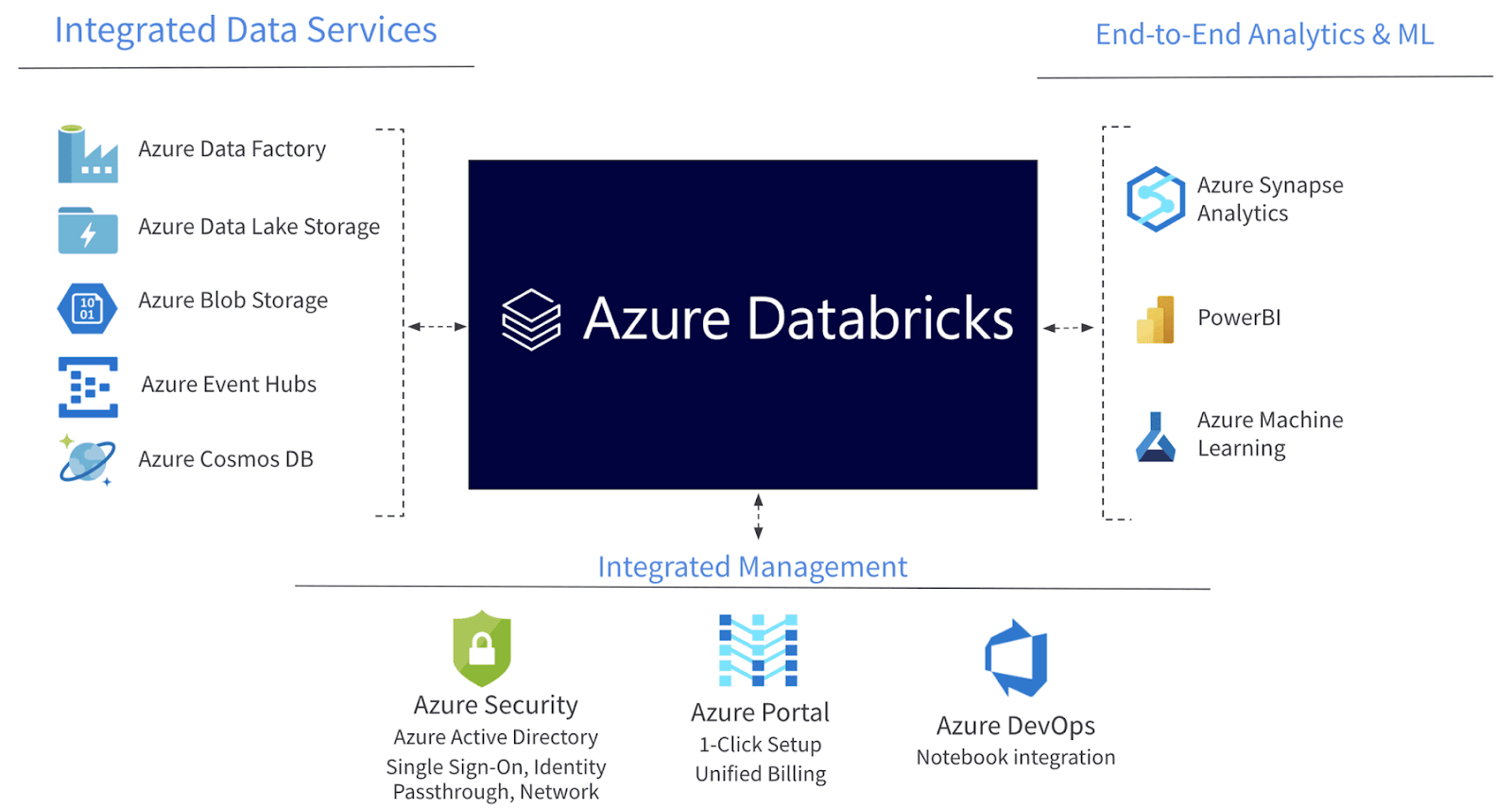
Source: Databricks
Azure Blob Storage
Azure Databricks integrates with Azure Blob Storage, which provides cost-effective storage and features like data redundancy and durability. This integration allows for the storage and retrieval of large amounts of unstructured data, including logs, images, and text.
Azure Data Lake Storage
Azure Databricks also integrates with Azure Data Lake Storage, an enterprise-wide hyper-scale repository for big data analytic workloads. This integration allows businesses to perform analytics on data of any size, type, and ingestion speed in a single place.
Azure SQL Data Warehouse
The integration of Azure Databricks with Azure SQL Data Warehouse allows for the creation of a modern data warehouse that can process large volumes of data. This integration allows for fast querying and optimized storage, thereby making the data easily accessible and usable.
Setting Up Azure Databricks In Your Own Virtual Network
Step 1: Create a Virtual Network
In Azure, a virtual network (VNet) is a representation of your own network in the cloud. It is a logical isolation of the Azure cloud dedicated to your subscription. A VNet enables many types of Azure resources, such as Azure Virtual Machines (VM), to securely communicate with each other, the internet, and on-premises networks.
To create a virtual network, you need to log in to the Azure portal and choose Create a resource. Search for Virtual network and select it. You’ll be required to fill in details like the name, address space, subscription, resource group, location, subnet name, and address range. Ensure to input all these details correctly.
Once you’re done, go to the Review + create tab and click on Create and wait for the deployment to be completed. Note the virtual network name, the resource group name, and the location, you’ll need these details in the next step.
Step 2: Create an Azure Databricks Workspace
Once you’ve successfully created a virtual network, the next step is to create an Azure Databricks workspace. Azure Databricks workspace is an environment for running your Apache Spark jobs. It provides a central place to manage all your Spark applications and allows you to manage data and compute resources for your project.
Navigate to the Azure portal and choose Create a resource. Next, go to Analytics and then Databricks. Search for Azure Databricks Service and select it. Under the Basics tab, you’ll be required to fill in details like the workspace name, subscription, resource group (use the one created in the previous step), location (should be in the same region as the virtual network), and pricing tier.
Under the Networking tab, fill in details including virtual network (select the one created in the previous step) and subnet.
Once you’ve filled in these details, click on Create and wait for the deployment to be completed. After the workspace is created, you can launch it by clicking on Launch workspace. This will open the Databricks workspace in a new tab.
Step 3: Create a Cluster
The final step is to create a cluster. A cluster in Azure Databricks is a set of computation resources and configurations on which you run data engineering, machine learning, and data analytics workloads, such as production ETL pipelines.
To create a cluster, navigate to your Databricks workspace and select the Clusters option from the side menu. Click on Create cluster and fill in details like the cluster name, runtime version, python version, and the number of workers. Once you’ve filled in these details, click on Create cluster.
Wait for a few minutes for the cluster to be created. Once it’s ready, you can start running your Spark jobs on it.
Autonomous Databricks Optimization Solutions
For the next level of optimizing Databricks workloads, there are autonomous, continuous solutions that can improve speed and reduce costs. Intel Granulate continuously and autonomously optimizes large-scale Databricks workloads for improved data processing performance.
With the Intel Granulate optimization solution, companies can minimize processing costs across Spark workloads in Databricks environments and allow data engineering teams to improve performance and reduce processing time.
By continuously adapting resources and runtime environments to application workload patterns, teams can avoid constant monitoring and benchmarking, tuning workload resource capacity specifically for Databricks workloads.