
What Is Databricks Optimization?
Databricks optimization refers to the process of improving the performance, efficiency, and cost-effectiveness of data processing, analytics, and machine learning workloads running on the Databricks platform. Databricks is a unified analytics platform built on top of Apache Spark, which provides a managed and scalable environment for big data processing and machine learning tasks.
Optimizing Databricks involves various techniques and best practices that can help organizations maximize the value of their Databricks workloads while minimizing resource utilization and costs.
For more background, see our complete guide to the Databricks platform.
This is part of an extensive series of guides about AI technology.
In this article:
Why Is Databricks Optimization Important?
Databricks optimization is essential for several reasons, as it helps organizations maximize the value of their data processing, analytics, and machine learning workloads while minimizing resource utilization and costs. Some key benefits of Databricks optimization include:
- Improved performance: Optimizing Databricks workloads can significantly enhance the performance of data processing and analytics tasks, enabling organizations to process larger volumes of data and obtain insights faster.
- Cost reduction: Optimizing resource utilization, data storage formats, and query execution can help reduce the costs associated with running Databricks workloads, including compute, storage, and data transfer expenses.
- Scalability: Databricks optimization enables organizations to scale their data processing and analytics workloads more efficiently, accommodating growing data volumes and increasing demands without sacrificing performance or incurring excessive costs.
- Enhanced reliability: By optimizing Databricks workloads and configurations, organizations can minimize the risk of performance bottlenecks, resource contention, and other issues that can impact the reliability and stability of their data processing and analytics tasks.
- Better resource allocation: Optimizing Databricks workloads allows organizations to allocate their resources more effectively, ensuring that compute, memory, and storage resources are used efficiently and prioritized according to workload requirements.
- Faster development cycles: Improved performance and efficiency can help accelerate the development and deployment of data processing, analytics, and machine learning solutions, enabling organizations to bring new products and services to market faster.

Databricks Optimization Techniques and Best Practices
Select the Right VM Size and Type
When running Databricks in the cloud, it’s essential to choose the right VM size and type for your workload. The VM size and type you select can significantly impact the performance and cost of your Databricks workloads. There are many factors to consider when selecting a VM, including the memory and CPU requirements of your workload, the nature of your workload (whether it’s CPU-intensive, memory-intensive, or IO-intensive), and the cost.
For instance, for CPU-intensive workloads, you might want to opt for compute-optimized VMs, which offer a high CPU-to-memory ratio. On the other hand, for memory-intensive workloads, memory-optimized VMs, which provide a high memory-to-CPU ratio, might be more appropriate. It’s also worth noting that the VM size and type you choose can affect the scalability of your clusters. Therefore, it’s crucial to choose a VM size and type that can accommodate your workload’s scaling requirements.
Learn more in our detailed guide to Azure Databricks pricing
Use Adaptive Query Execution
Adaptive Query Execution (AQE) in Databricks is a dynamic optimization feature that adjusts query execution plans at runtime based on the actual data being processed. By adapting to the data characteristics and runtime conditions, AQE improves performance and prevents out-of-memory errors.
AQE optimizes performance in several ways:
- Dynamically coalescing shuffle partitions: Combines small partitions to reduce the number of tasks and data shuffling, leading to better resource utilization and reduced overhead.
- Adaptive join strategy: Selects the most efficient join strategy (e.g., broadcast join, sort-merge join) based on actual input data sizes, preventing the wrong strategy from causing out-of-memory errors or slow performance.
- Skew join optimization: Detects and mitigates data skew by dividing skewed partitions into smaller sub-partitions, ensuring more balanced processing and reducing bottlenecks.
- Dynamic partition pruning: Prunes unnecessary partitions at runtime using runtime filter values, reducing the amount of data read and processed, thus saving time and resources.
Use the Photon Engine
Photon is Databricks Lakehouse’s next-generation engine designed to accelerate the performance of data processing and analytics workloads. Built from the ground up in C++, Photon leverages modern hardware features, vectorized query execution, and sophisticated optimization techniques to deliver high performance for both Delta Lake and Parquet formats.
Photon is useful for several reasons:
- Vectorized query execution: Processes data in a columnar format, allowing it to perform operations on multiple data elements simultaneously. This vectorization takes advantage of modern CPU features like SIMD (Single Instruction, Multiple Data), which leads to substantial performance improvements.
- Faster writing to Delta and Parquet: Optimizes the write operations for both Delta Lake and Parquet formats, ensuring efficient storage and better performance when reading and writing large-scale data.
- Enhanced performance for query execution: Incorporates advanced query optimization techniques like predicate pushdown, join reordering, and filter propagation. These optimizations minimize data movement and computation, resulting in faster query execution.
- Multi-language support: Integrates with multiple programming languages, including Python, Scala, and SQL. This allows users to leverage their preferred language while still benefiting from the performance enhancements provided by Photon.
- Improved resource utilization: Photon’s optimization techniques enable more efficient use of available resources, reducing overall infrastructure costs and improving the scalability of data processing workloads.
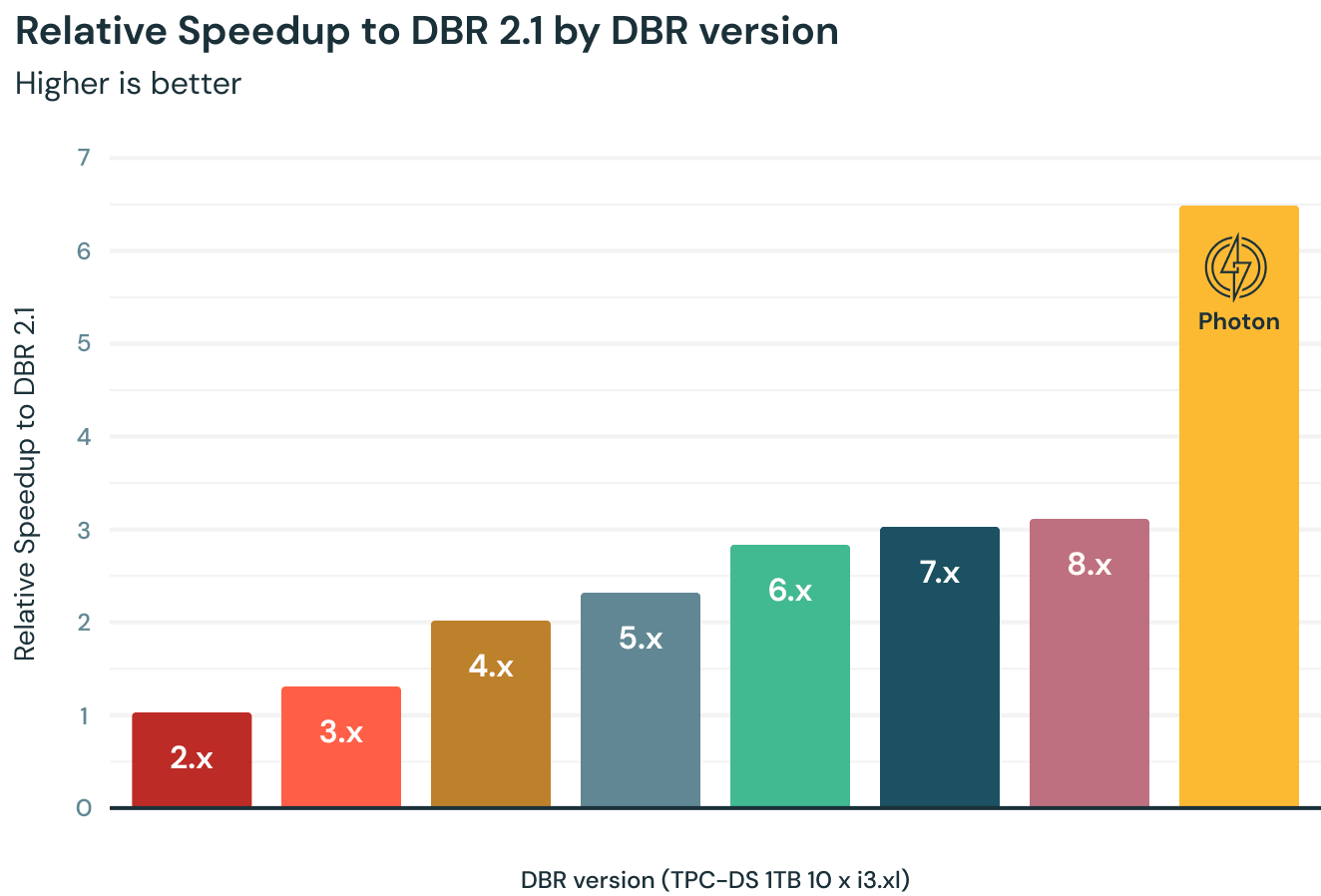
Image Source: Databricks
Leverage the Delta Cache
Delta Cache is a feature in Databricks that enables efficient caching of data, providing substantial performance improvements for repetitive queries and iterative workloads. It caches the most frequently accessed data from Delta Lake tables or Parquet files, storing it either in memory or on high-speed local storage devices like NVMe SSDs.
Delta Cache is important to use for several reasons:
- Improved query performance: By caching frequently accessed data, Delta Cache reduces the need to read data repeatedly from remote storage systems. This results in faster query execution and more efficient use of resources.
- Reduced latency: As data is stored closer to the compute nodes, the time taken to access the data is significantly reduced, leading to lower latency and improved user experience.
- Enhanced iterative workloads: Machine learning and data science workloads often involve iterative algorithms, which benefit significantly from caching. The cache reduces the time spent reading data for each iteration.

Enable Automatic Optimization
Auto Optimize is a feature in Databricks that automates the optimization of data storage in Delta Lake tables, making it easier to maintain and improve the performance of read operations. Auto Optimize achieves this by automatically handling two key processes:
- Optimized writes: Consolidate small files produced during write operations into larger files. This process reduces the overall number of files in the Delta Lake, making it easier for the engine to read and process the data. By organizing data into larger files, Auto Optimize minimizes the overhead associated with managing numerous small files, which can lead to degraded read performance.
- Automatic compaction: Automatically compacts small files into larger ones during the background optimization process. This compaction is essential for maintaining optimal read performance over time, as it helps to reduce the fragmentation of data that can occur as more files are added, updated, or deleted. Compaction ensures that data is stored in a more efficient and organized manner, which in turn accelerates read operations.
While Auto Optimize can add some latency overhead to write operations, it is designed to minimize the impact on performance. The optimization processes run asynchronously in the background, meaning that they do not block or interfere with ongoing write operations. Auto Optimize also leverages cluster resources intelligently, dynamically adjusting its resource usage based on the workload’s requirements and the cluster’s capacity.
Leverage Autoscaling
The autoscaling feature in Databricks enables efficient resource utilization, reduces costs, and automatically adjusts cluster capacity to handle varying workloads. Autoscaling helps maintain optimal performance by scaling the number of worker nodes in a cluster based on the demands of the workload.
Autoscaling works by monitoring the cluster’s resource usage and adding or removing worker nodes as needed. Users must specify the minimum and maximum number of nodes in a cluster to set the scaling boundaries. This ensures that the cluster scales within an acceptable range, preventing overuse or underutilization of resources.
Time-based autoscaling is an additional option that allows users to schedule scaling events based on time. This feature is useful for anticipating predictable workload changes, such as daily or weekly patterns, and proactively scaling the cluster to accommodate those demands.
By utilizing autoscaling, Databricks users can optimize performance, minimize costs, and adapt to changing workloads more efficiently.
Tag the Clusters
Cluster tagging is important for optimizing Databricks resource usage because it helps users organize, track, and manage clusters effectively. By assigning tags to clusters, users can categorize resources based on their purpose, team, project, or other relevant attributes.
Tagging policies ensure that users follow a consistent and standardized approach to tagging resources. This consistency enables better reporting, monitoring, and cost allocation.
Team-specific tags are particularly useful in organizations with multiple teams sharing a Databricks workspace. These tags facilitate resource attribution to individual teams, helping to monitor usage, enforce resource limits, and optimize costs. In summary, cluster tagging plays a crucial role in managing and optimizing resource usage in Databricks.
Autonomous Continuous Optimization
Continuous optimization is a process of continually refining and improving the performance and efficiency of data analytics workloads running on the Databricks platform. It involves constantly monitoring the performance of the system and making adjustments to optimize performance and reduce costs.
Autonomous optimization in Databricks with Intel Granulate is achieved through the use of machine learning algorithms and AI-driven automation. These tools analyze the system and workload metrics to identify patterns and trends, and make recommendations for optimization.
To achieve continuous optimization, runtime environments and resources must be continually adapted to the changing demands of the application workloads. This involves adjusting cluster configurations, optimizing data processing pipelines, and fine-tuning Spark configurations to ensure optimal performance and cost efficiency. By continuously optimizing Databricks workloads, users can ensure that they are getting the most out of their cloud resources and maximizing the value of their data analytics projects.
Learn more in our detailed guide to Databricks performance tuning (coming soon)
See Additional Guides on Key AI Technology Topics
Together with our content partners, we have authored in-depth guides on several other topics that can also be useful as you explore the world of AI technology.
Explainable AI
Authored by Kolena
- Feature Importance: Methods, Tools, and Best Practices
- Explainable AI Tools: Key Features & 5 Free Tools You Should Know
- 7 Pillars of Responsible AI
Machine Learning Engineering
Authored by Run.AI
- What is a Machine Learning Engineer? The Ultimate Guide
- Machine Learning Infrastructure: Components of Effective Pipelines
- Machine Learning Automation for Faster Data Science Pipelines
MLOps
Authored by Run.AI