
Artificial Intelligence (AI) is revolutionizing industries across the globe, but developing AI applications is not without its challenges. According to the ML Insider Survey, 26% of large companies are running 50 or more ML models in their organization, but 62% of AI professionals continue to say it is difficult to execute a successful AI project. As Intel Software’s flagship Performance product, Intel Granulate offers a suite of optimization solutions for AI use cases.
Focusing on Spark-based AI workloads, Intel Granulate’s Runtime, Big Data, and Databricks optimization solutions offer real-time, continuous enhancement, driving application performance while cutting costs. Keep in mind that, while Intel Granulate can lead to up to 45% cost reductions and 23% improvement in average processing time for CPU workloads, not GPUs.
In this series, we’ll start by exploring the optimization of Machine Learning (ML).
Benefits of Optimizing Machine Learning
Increased Throughput and Faster Job Completion Time
Optimizing ML leads to enhanced CPU throughput, which accelerates the training and prediction phases of machine learning models. This increase in throughput directly translates to faster job completion times, a critical factor in time-sensitive AI projects.
Increased throughput in Machine Learning applications is vital because it directly influences the efficiency and effectiveness of the learning process. Higher throughput means more data can be processed in a shorter amount of time, allowing ML models to be trained and refined quicker and more comprehensively.
This is particularly important in dealing with large datasets, common in many ML applications, where the ability to process vast amounts of information swiftly leads to more accurate and robust models. Furthermore, increased throughput enables real-time data processing, crucial in applications like fraud detection, autonomous vehicles, or live recommendation systems, where immediate data analysis and action are required. In essence, boosting throughput in ML not only speeds up model training and inference but also enhances the overall performance and reliability of AI systems in dynamic, data-intensive environments.
Energy Usage and Sustainability
Energy efficiency is critical in ML operations. Optimizing CPUs for better power efficiency allows for longer and more intense training sessions, significantly reducing the risk of overheating and high energy costs. This approach not only boosts performance but also supports sustainability efforts.
Decreased energy usage and improved sustainability in Machine Learning applications are increasingly important due to environmental and economic factors. ML, particularly deep learning, often requires extensive computational power, leading to high energy consumption and associated costs. By optimizing these applications for lower energy usage, organizations can significantly reduce their carbon footprint and operational expenses, aligning with global efforts towards environmental sustainability.
Moreover, energy-efficient ML models are essential for scalability, as they enable the deployment of more models or larger models without proportionate increases in power demand. This efficiency is crucial not only for large data centers but also for edge computing devices, where power availability is limited. Thus, energy-efficient ML practices contribute to both ecological responsibility and long-term financial viability, ensuring that the benefits of AI are harnessed in a sustainable and cost-effective manner.
Mobileye Optimizes Machine Learning Models With Intel Granulate
Mobileye, a pioneer in autonomous driving technology, faced the challenge of optimizing machine learning models within a low-power chip for tasks like advanced driver assist systems (ADAS) and full robotaxis. A significant breakthrough was the development of high-definition maps for autonomous driving, known as REM or Road Experience Management™.
These intricate maps, containing detailed road information, were created using data gathered from consumer ADAS systems. However, traditional mapping methods proved inefficient and costly. REM tackled this by using data from cameras, sensors, and lidar in consumer vehicles, compressing it into a compact format. With the scale of REM growing rapidly, from thousands of vehicles in 2018 to 1.5 million by 2023, Mobileye faced increasing challenges in managing the growing quantity and complexity of data, which in turn escalated costs.
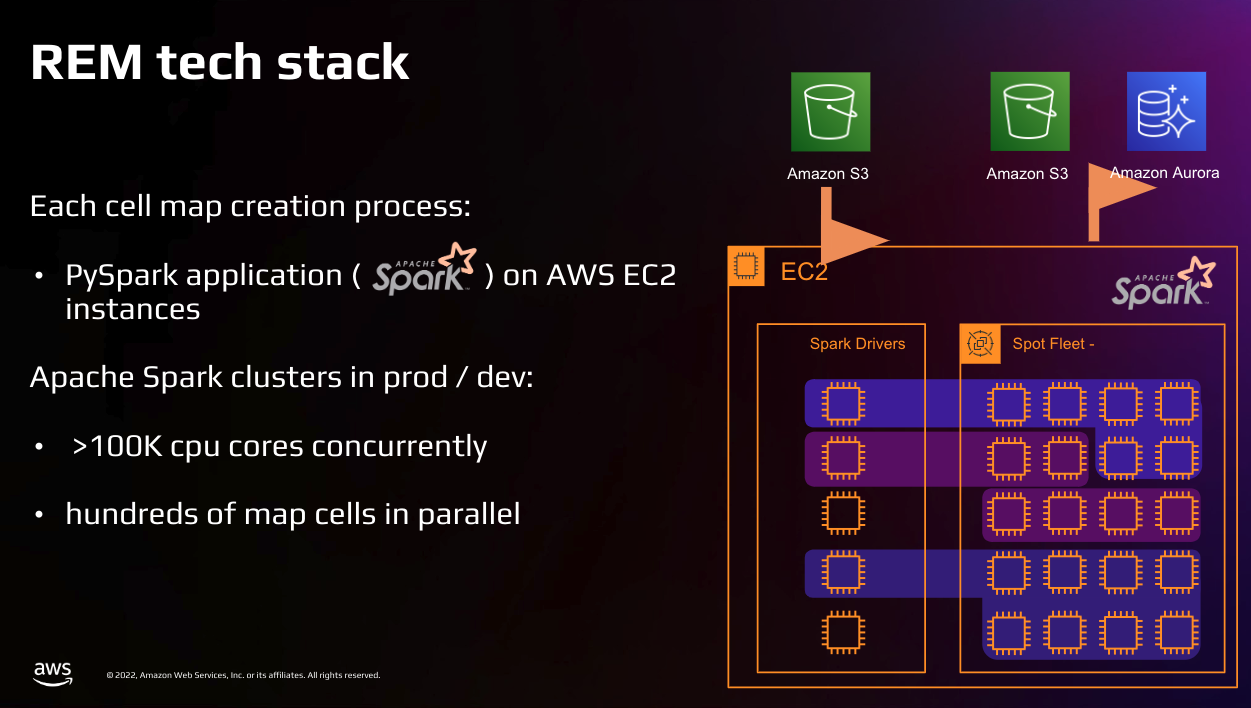
To manage these escalating costs, Mobileye focused on optimizing the average CPU hours required to produce a single kilometer of a lane. This was crucial because the bulk of REM’s costs lay in the CPU compute of the EC2 instances.
However, as Mobileye’s operations expanded, processing a vast amount of data – 14 billion kilometers of road data by 2023 – became increasingly expensive. Additionally, the demand for new map features and frequent changes in the code base presented significant development challenges. The need for rapid implementation of new map features, coupled with the necessity to keep up with changing road conditions, meant that Mobileye had to find a way to optimize before scaling further to manage costs effectively.
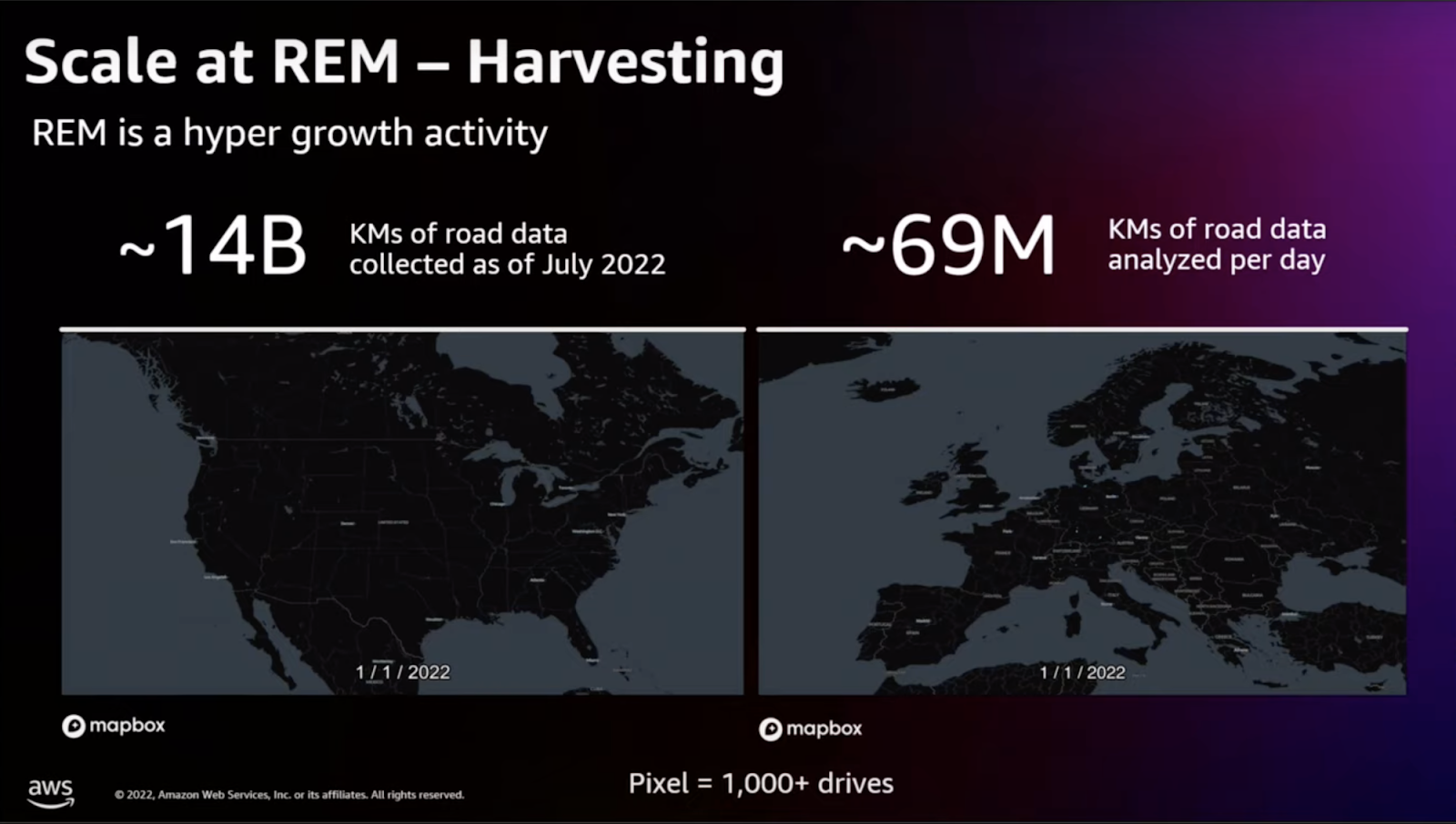
To address these challenges, Mobileye partnered with Intel Granulate, resulting in a 45% reduction in CPU hours and cost for EC2-related items. A notable incident where Intel Granulate was turned off during a test phase, leading to almost doubled CI test durations, further underscored the significant efficiency gains and cost savings achieved through this partnership.

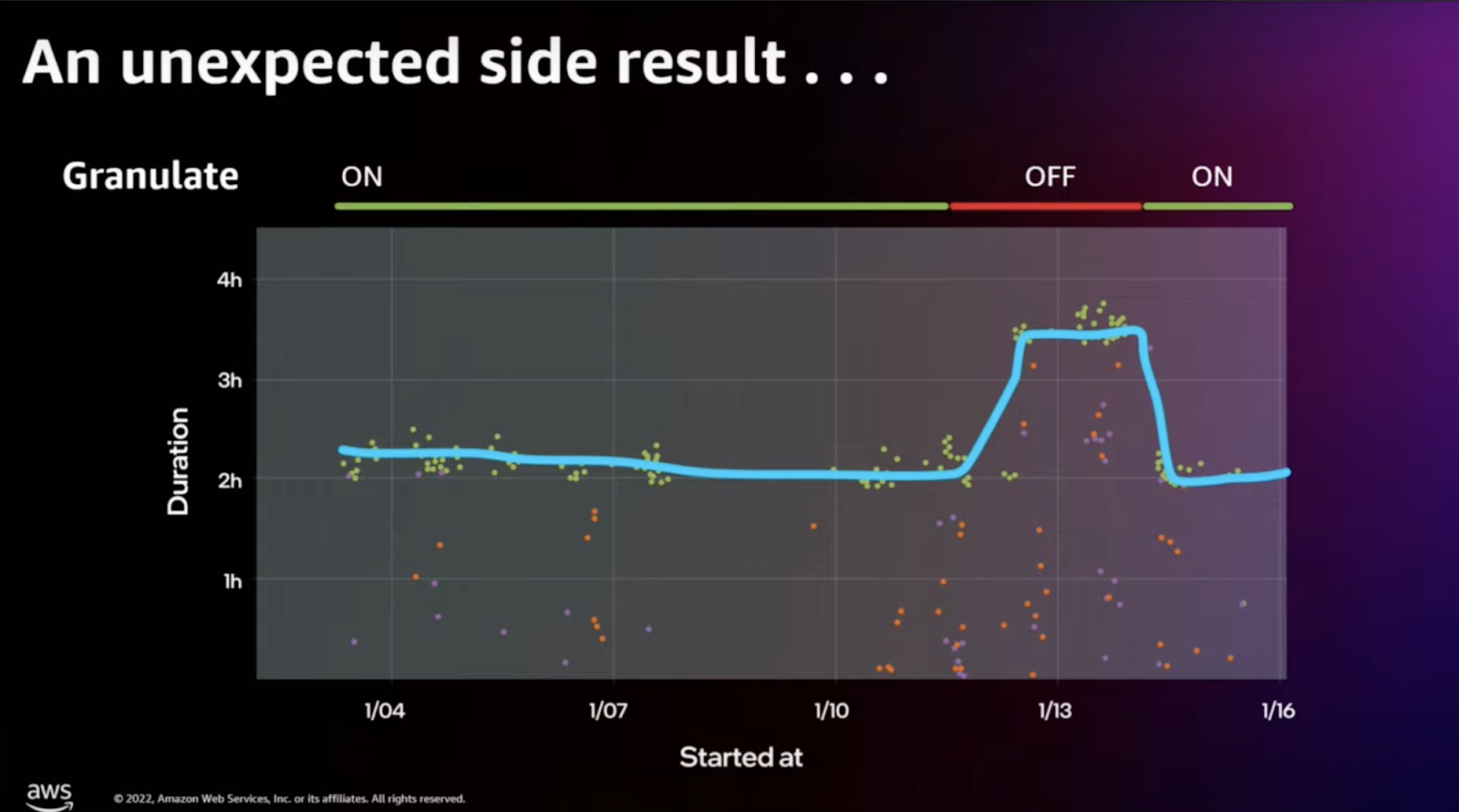
Mobileye’s collaboration with Intel Granulate not only resolved their immediate challenges but also set a new standard for industry-wide innovation and cost-effective scaling in the realm of autonomous driving technology.
Intel Granulate Solutions that Improve ML Performance
- Runtime / JVM – For ML applications, especially those dependent on Java Virtual Machines (JVM), runtime optimization is crucial. Intel Granulate’s solutions fine-tune JVM settings to ensure peak performance for ML tasks. Learn more here.
- Big Data – Handling big data efficiently is a core requirement of ML. Intel Granulate’s Big Data optimization tools are designed to process large datasets more effectively, enhancing the overall performance of ML applications. Learn more here.
- Databricks – Databricks, a popular platform for big data processing and ML, also benefits from Intel Granulate’s optimization. Intel Granulate optimizes Databricks data management operations and is part of the Databricks Partner Program, ensuring seamless integration and that these environments run efficiently, leveraging the full potential of ML models. Learn more here.
Impact of Autonomous Optimization on ML Applications
Intel Granulate’s application performance optimization is a game-changer for CPU-based AI applications. It provides tangible solutions that enhance performance and reduce costs, adding significant value to a variety of AI applications.
- Optimized CPU Utilization – Intel Granulate’s solutions enhance CPU performance specifically for Spark workloads. This ensures efficient processing for AI and ML applications, leading to more effective use of computational resources.
- Cost-Effective Resource Management – With global spending on AI set to reach $154 billion in 2023, managing costs effectively is more important than ever. Intel Granulate aids in reducing operational costs through smart resource allocation and management, tailored for Spark’s in-memory processing.
- Improved Scalability and Elasticity – The platform allows for the seamless definition of executor characteristics and automatically adjusts autoscaling. This is essential for handling scalability and adapting to varying workloads in ML operations.
- Streamlined Spark Operations – Intel Granulate simplifies the complexity involved in the configuration and tuning of Spark jobs. This streamlining results in optimal performance, crucial for the success of ML applications.
- Enhanced Data Processing Speeds – One of the key benefits of Intel Granulate’s optimization is the increased throughput and efficiency in data processing. This is particularly important for CPU-intensive tasks in Spark-based ML operations.
As AI and ML continue to advance, optimizing these technologies becomes increasingly important. Intel Granulate’s suite of optimization tools provides a comprehensive solution for enhancing ML application performance, ensuring cost-effectiveness, and promoting sustainability.
Through improved throughput, energy efficiency, and streamlined operations, Intel Granulate empowers organizations to harness the full potential of their AI and ML investments, driving innovation and success in this rapidly evolving field.