

What Is Apache Spark Streaming (Spark Structured Streaming)?
Apache Spark Streaming is a real-time data processing framework that enables developers to process streaming data in near real-time. It is a legacy streaming engine in Apache Spark that works by dividing continuous data streams into small batches and processing them using batch processing techniques.
However, Spark Streaming has some limitations, such as lack of fault-tolerance guarantees, limited API, and lack of support for many data sources. It has also stopped receiving updates.
Spark Structured Streaming is a newer and more powerful streaming engine that provides a declarative API and offers end-to-end fault tolerance guarantees. It leverages the power of Spark’s DataFrame API and can handle both streaming and batch data using the same programming model. Additionally, Structured Streaming offers a wide range of data sources, including Kafka, Azure Event Hubs, and more.
In this article:
- Spark Structured Streaming Use Cases
- Benefits of Spark Streaming
- Spark Structured Streaming Operating Model
- Spark Structured Streaming: Quick Tutorial
Spark Structured Streaming Use Cases
Spark Structured Streaming is a powerful tool for processing real-time data streams, and it has a wide range of use cases in various industries. Here are some examples of Spark Structured Streaming use cases:
- Fraud detection: Spark Structured Streaming can be used to detect fraud in real-time data streams, such as credit card transactions or insurance claims. It can identify patterns and anomalies in the data and trigger alerts or automated actions when suspicious activity is detected.
- Real-time analytics: Spark Structured Streaming can be used for real-time analytics and business intelligence applications, such as monitoring website traffic, analyzing customer behavior, or tracking supply chain operations. It provides real-time insights that can help organizations make faster and more informed decisions.
- IoT analytics: Spark Structured Streaming can be used to process and analyze real-time data from IoT sensors and devices. It can help organizations monitor and optimize industrial processes, smart home automation, and predictive maintenance.
- Video and audio streaming: Spark Structured Streaming can be used to process real-time video and audio streams, such as security camera footage, video conferencing, or live streaming events. It can provide real-time analysis and insights that can be used for surveillance, security, or audience engagement.

Benefits of Spark Streaming
The key benefits of Spark Streaming include:
- Low latency: Spark Structured Streaming achieves low latency through its micro-batching approach. This technique divides the incoming data stream into small, manageable batches that are processed in near real-time. By processing these micro-batches quickly and efficiently, Spark Structured Streaming minimizes the time between data ingestion and result generation.
- Flexibility: Spark Structured Streaming accommodates a wide range of data sources and formats. It supports integration with popular data sources such as Kafka, Kinesis, Azure Event Hubs, and various file systems. The unified API for batch and stream processing means that developers can maintain a single codebase for both historical and real-time data.
- Real-time processing: Structured Streaming continuously processes data as it arrives, providing organizations with the ability to gain immediate insights and take action based on current information. For example, in IoT applications, Spark Structured Streaming can process and analyze data from sensors in real-time, enabling predictive maintenance and optimization of industrial processes.
- Integration with other Spark components: Spark Structured Streaming is designed to work seamlessly with other components of the Apache Spark ecosystem. This includes Spark SQL for querying structured data, MLlib for machine learning tasks, and GraphX for graph processing.
Kafka Streams vs. Spark Streaming: What Are the Differences?
Focus and use cases:
- Kafka Streams is a lightweight, library-based stream processing tool that operates on data directly within Kafka. It employs a continuous processing model, where records are processed as they arrive, which provides low-latency processing. This makes Kafka Streams particularly well-suited for applications that require real-time event processing and transformations with tight integration to Kafka, such as monitoring, alerting, and simple real-time data transformations.
- Spark Structured Streaming employs a micro-batching model, grouping incoming data into small batches and processing them at regular intervals. This approach leverages Spark’s powerful distributed computing framework, which allows for handling large-scale data processing tasks. Spark Structured Streaming provides an API that integrates well with the broader Spark ecosystem, making it ideal for more complex stream processing tasks, including real-time analytics, machine learning, and ETL processes.
Scalability and fault tolerance:
- Kafka Streams is designed for high-throughput stream processing with built-in fault tolerance mechanisms through Kafka’s replication and partitioning features. It ensures that the stream processing tasks are resilient to node failures and can recover quickly without data loss.
Spark Structured Streaming, leveraging Spark’s distributed architecture, offers robust scalability and fault tolerance, providing exactly-once processing semantics. This ensures that data is processed correctly even in the face of system failures, which is critical for applications that require high reliability and consistency.
Spark Structured Streaming Operating Model
Spark Structured Streaming handles live data streams by dividing them into micro-batches and processing them as if they were a batch query on a static table. The resulting output is continuously updated as new data arrives, providing real-time insights on the data. This streaming data processing model is similar to batch processing.
Handling Input and Output Data
Here are some of the basic concepts in Structured Streaming:
Input Table
In Spark Structured Streaming, the input data stream is treated as an unbounded table that can be queried using Spark’s DataFrame API. Each micro-batch of data is treated as a new “chunk” of rows in the unbounded table, and the query engine can generate a result table by applying operations to the unbounded table, just like a regular batch query. The result table is continuously updated as new data arrives, providing a real-time view of the streaming data.
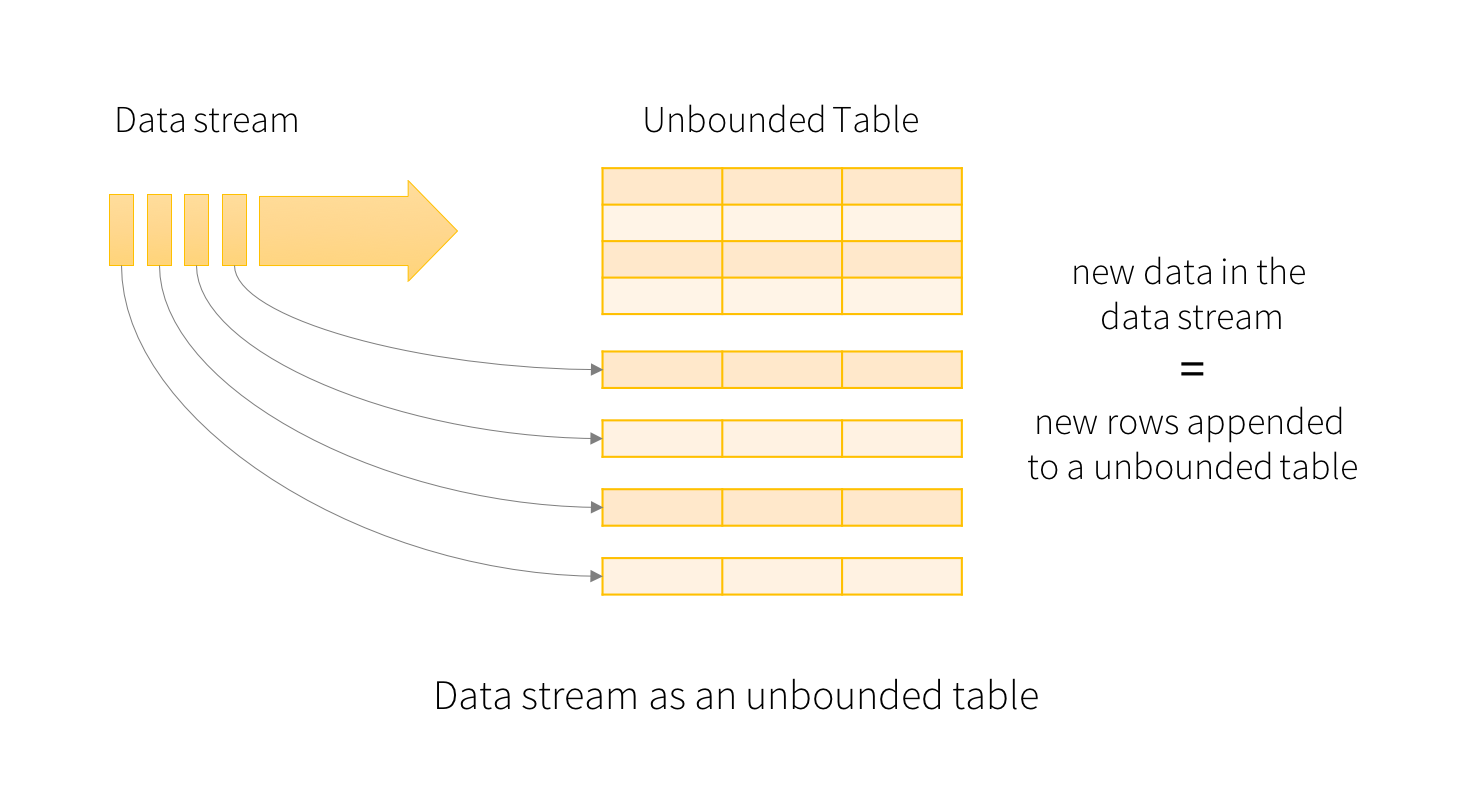
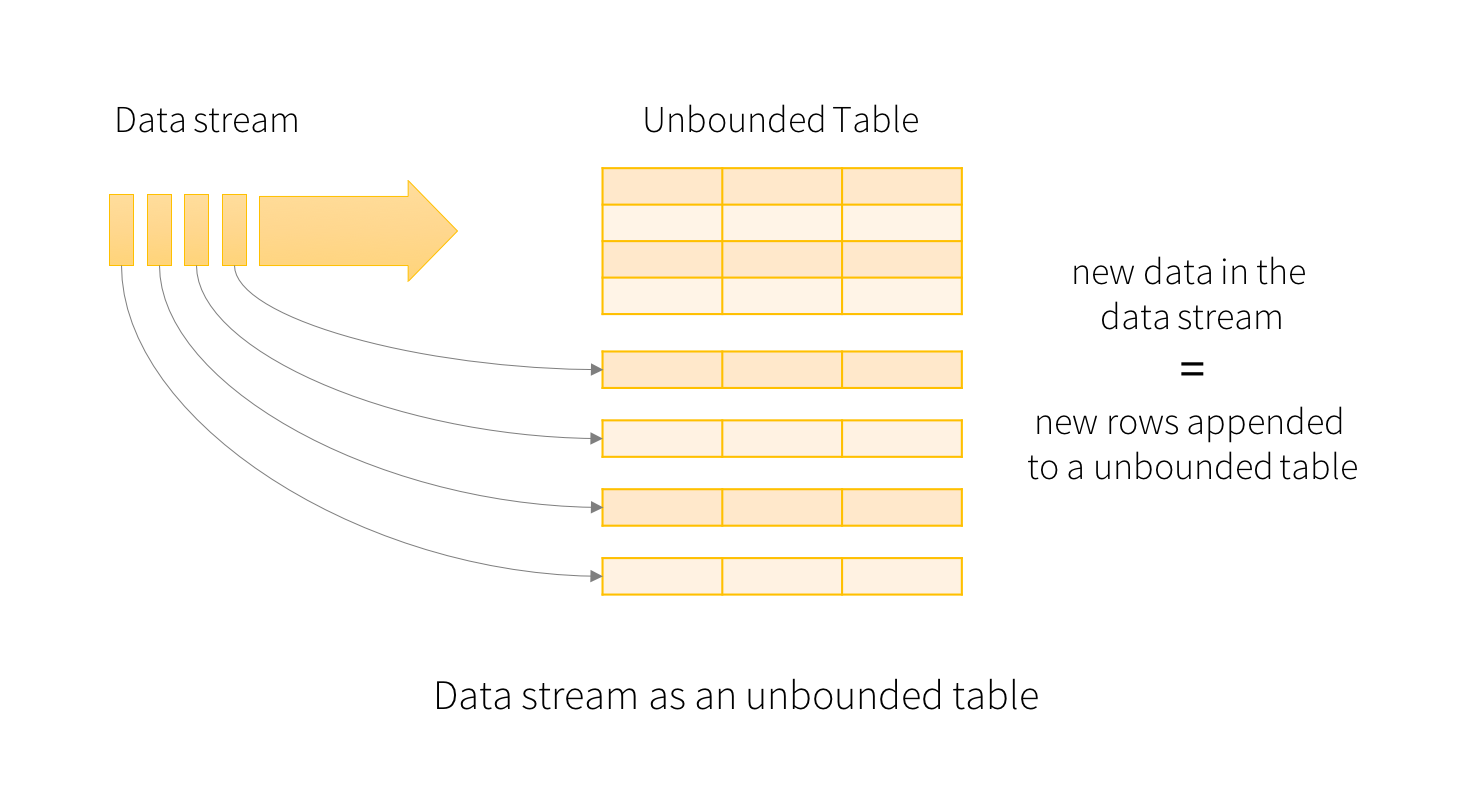{kind=link}
Output
In Structured Streaming, the output is defined by specifying a mode for the query. There are three output modes available:
- Complete mode: In this mode, the output table contains the complete set of results for all input data processed so far. Each time the query is executed, the entire output table is recomputed and written to the output sink. This mode is useful when you need to generate a complete snapshot of the data at a given point in time.
- Update mode: In this mode, the output table contains only the changed rows since the last time the query was executed. This mode is useful when you want to track changes to the data over time and maintain a history of the changes. The update mode requires that the output sink supports atomic updates and deletes.
- Append mode: In this mode, the output table contains only the new rows that have been added since the last time the query was executed. This mode is useful when you want to continuously append new data to an existing output table. The append mode requires that the output sink supports appending new data without modifying existing data.
The choice of mode depends on the use case and the capabilities of the output sink. Some sinks, such as databases or file systems, may support only one mode, while others may support multiple modes.
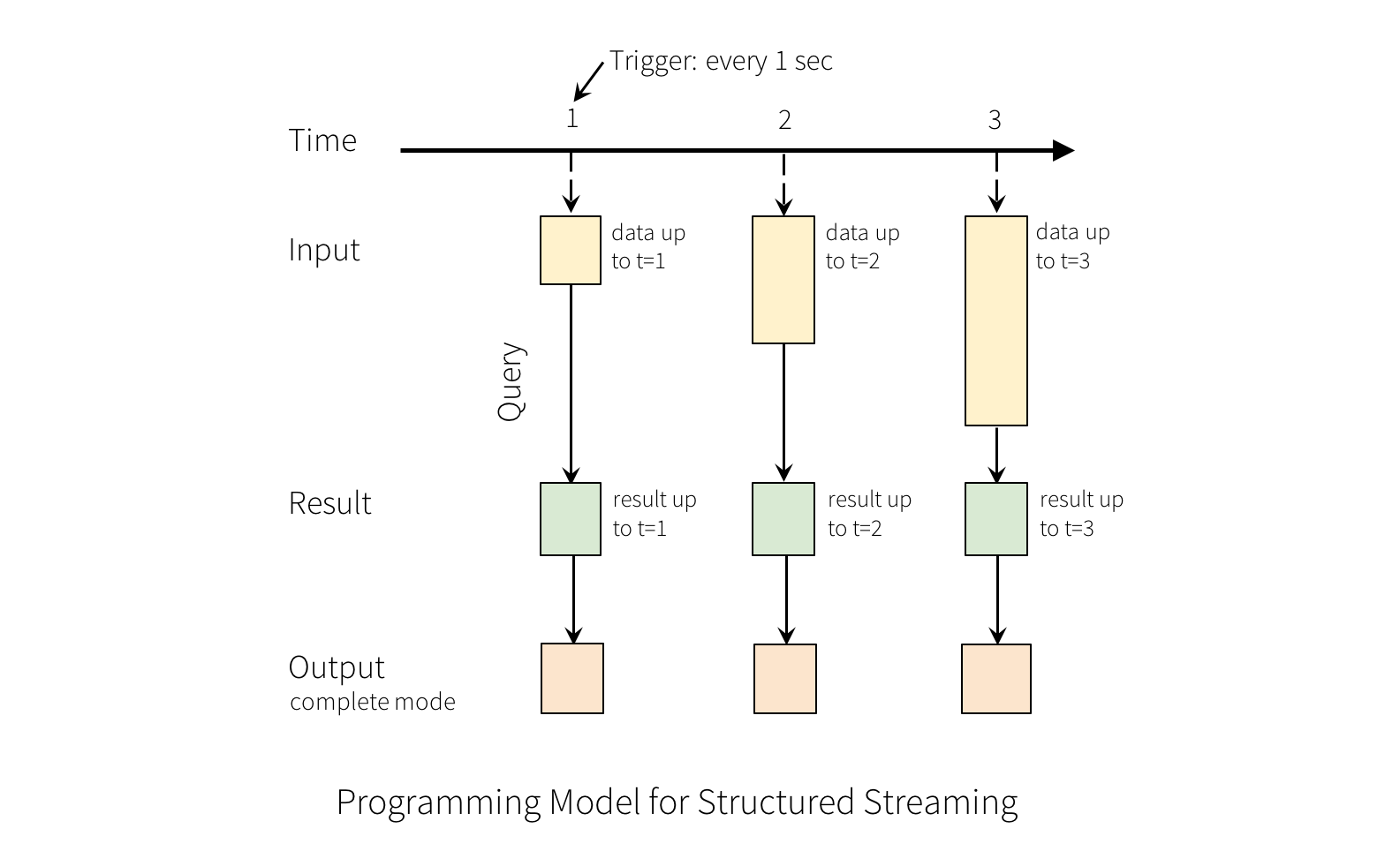
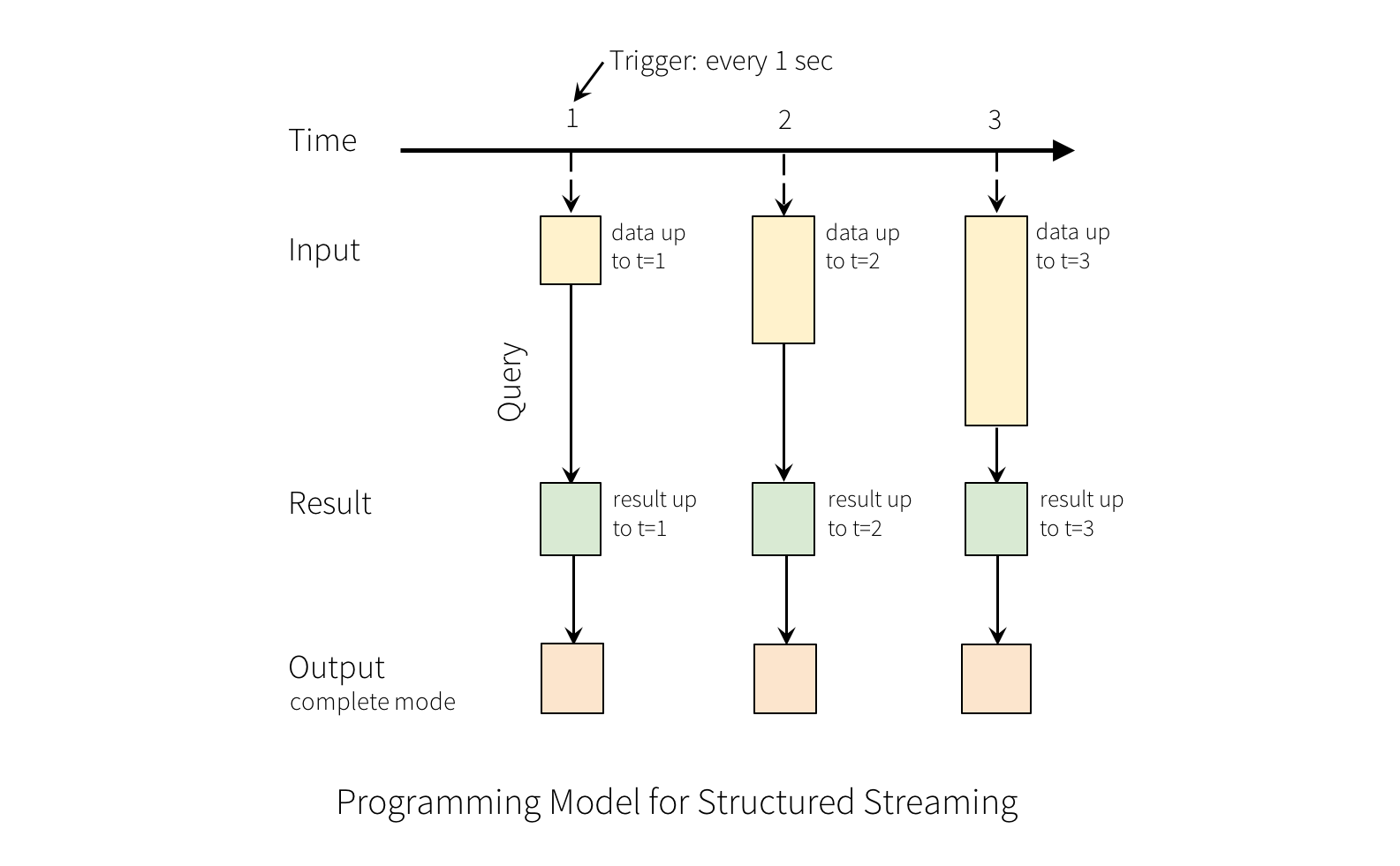{kind=link}
Handling Late and Event-Time Data
Event-time data is a concept in stream processing that refers to the time when an event actually occurred. It is usually different from the processing time, which is the time when the system receives and processes the event. Event-time data is important in many use cases, including IoT device-generated events, where the timing of events is critical.
Late data is the data that arrives after the time window for a particular batch of data has closed. It can occur due to network delays, system failures, or other factors. Late data can cause issues in processing if not handled correctly, as it can result in incorrect results and data loss.
Using an event-time column to track IoT device-generated events allows the system to accurately process events based on when they actually occurred, rather than when they were received by the system.
Fault Tolerance Semantics
Fault tolerance semantics refers to the guarantees that a streaming system provides to ensure that data is processed correctly and consistently in the presence of failures, such as network failures, node failures, or software bugs.
Idempotent streaming sinks are a feature of fault-tolerant streaming systems that ensure that data is written to the output sink exactly once, even in the event of failures. An idempotent sink can be called multiple times with the same data without causing duplicates in the output. Fault-tolerance semantics – such as end-to-end one-time semantics – provide a high degree of reliability and consistency in streaming systems.
Spark Structured Streaming: Quick Tutorial
For this example, suppose you want to create a running wordcount of the text data received while listening via a TCP socket. The following demonstrates how you might express this function with Spark Structured Streaming.
Step 1: Importing
Start by importing the required classes and creating a SparkSession in your local environment, which will serve as the base for all Spark-related functionalities:
import org.apache.spark.sql.functions._
import org.apache.spark.sql.SparkSession
val spark = SparkSession
.builder
.appName(“WordcountTracker”)
.config(“spark.master”, “local”)
.getOrCreate()
import spark.implicits._
Step 2: Creating the Data Frame
Now you can create a streaming DataFrame to represent the text data sent by the listening server. In this example, the server uses localhost:9999. You can then transform the DataFrame and enable it to count words:
// Create DataFrame for the input text stream from the localhost:9999 connection
val lines = spark.readStream
.format(“socket”)
.option(“host”, “localhost”)
.option(“port”, 9999)
.load()
// Divide the text into words
val words = lines.as[String].flatMap(_.split(” “))
// Generate the running wordcount
val wordcounts = words.groupBy(“value”).count()
The “input stream” DataFrame will represent the unbounded table that contains the streaming data. The table includes a column of strings called “value”, with each line of text being represented by a row in the table. At this stage, the system is not yet receiving data, because it hasn’t been started – this is the necessary transformation setup.
This configuration converts the DataFrame to a String dataset – the .as[String] element – allowing you to apply a flatMap operation to divide the lines of text into individual words. The resulting “words” dataset contains every word as a separate data point. This setup also defines the “wordcounts” DataFrame – the system groups the individual values in the dataset (the words) and counts them. The streaming DataFrame represents the stream’s running wordcount.
Step 3: Implementing the Wordcount
Once you’ve set up the streaming data query, the model can start processing data to computing the running wordcount. Enable it to publish the output of the completed wordcounts to the console. You specify this using outputMode(“done”) and initiate the text streaming computation with the start() function:
// Initiate a query to print the running wordcounts to the console
val query = wordcounts.writeStream
.outputMode(“update”)
.format(“console”)
.start()
query.awaitTermination()
Once the code is executed, the system should have initiated the computation in the background. The query object provides a handle for this streaming query – in this example, we chose to wait for the query to terminate using the awaitTermination() function. The reason for this is to prevent the process from finishing while the query remains active.
Step 4: Executing the Code
You can execute this code example by compiling it in a Spark application or running the code after downloading Spark. This example uses the latter option, which will require a netcat to run as the data server. A netcat is a small utility available in most Unix-based systems. Use the following:
$ nc -lk 9999
Next, change into the directory containing the example code and type sbt to compile the code. In the sbt prompt, type run to execute the code. A new terminal window should appear.
To try the sample application, in the new terminal window, start typing random words. Once you are finished with the inputting text, switch to the second terminal and press Ctrl+C to stop processing. You will be presented with a summary table like the following:

The system should count and display the text entered in the terminal that runs the netcat server, updating the wordcount each second.
Spark Streaming with Intel Tiber App-Level Optimization
Intel Tiber App-Level Optimization optimizes Apache Spark on a number of levels. With Intel Tiber App-Level Optimization, Spark executor dynamic allocation is optimized based on job patterns and predictive idle heuristics. It also autonomously and continuously optimizes JVM runtimes and tunes the Spark infrastructure itself.
Learn more in our detailed guide to spark streaming