
What Is Databricks on AWS?
Databricks is an open platform, based on Apache Spark, that lets organizations build and deploy data, analytics, and AI solutions. It is commonly used for enterprise-grade, large scale data projects. Databricks on AWS is an Amazon Partner Solution created in collaboration between Databricks and AWS. Technically, it’s a CloudFormation template that lets you set up Databricks on AWS with the click of a button.
The Databricks on AWS solution integrates with various AWS services, making it a good choice for organizations already using AWS infrastructure. It’s a managed service, meaning AWS and Databricks takes care of the infrastructure management, freeing your data teams to focus on analyzing data and gaining insights.
Below is the AWS on Databricks solution architecture. As you can see, the Databricks clusters are deployed across two availability zones (AZs) in a private subnet, while a third availability zone provides a NAT gateway that allows connectivity with the Internet.
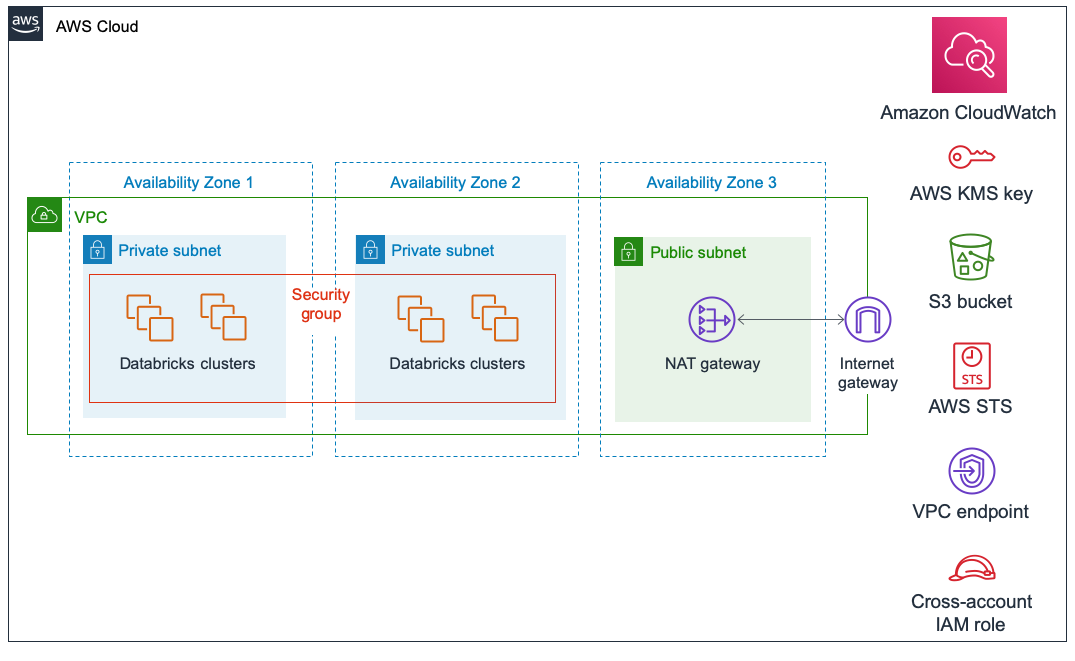
Source: AWS
This is part of a series of articles about databricks optimization
In this article:
- Key Features of Databricks on AWS
- Costs and Licensing
- Databricks Integration with AWS Services
- Setting Up Databricks on AWS
Key Features of Databricks on AWS
Let’s review some of the key features offered by Databricks on AWS.
Unified Analytics Platform
Databricks on AWS is a unified analytics platform that leverages the power of AWS while providing the advanced analytics capabilities of Databricks. The platform provides a collaborative workspace where data scientists, data engineers, and business analysts can work together on data and AI projects.
Optimized Apache Spark
Apache Spark is renowned for its speed and ease of use in big data processing, and Databricks has taken it a step further. The Databricks platform offers an optimized version of Apache Spark that delivers superior performance, helping you process large datasets faster and more efficiently. According to Databricks, its SQL-optimized compute clusters provide up to 12x better price/performance.

Delta Lake Integration
Databricks on AWS also integrates with Delta Lake, a storage layer that brings reliability to your data lakes. Delta Lake provides ACID transactions, scalable metadata handling, and unifies streaming and batch data processing. This integration allows you to build robust, reliable data pipelines, ensuring the integrity and quality of your data.
Built-In Data Connectors
Lastly, Databricks on AWS comes with built-in data connectors, making it easy to import data from various sources, both structured or unstructured. These connectors streamline the data ingestion process, making it easier to get your data into the platform and start analyzing it.
Costs and Licensing
Databricks on AWS offers a consumption-based pricing model, meaning that you only pay for what you use. It’s important to note that Databricks on AWS pricing includes not just the Databricks platform itself, but also the underlying AWS resources used to run it.
The platform is available as a Software as a Service (SaaS) offering, requiring no upfront investment or long-term commitment. Pricing is based on the Databricks products you choose to run on AWS. The table below summarizes the pricing as of the time of this writing.

Source: Databricks
Learn more in our detailed guide to Databricks pricing
Databricks Integration with AWS Services
Here are the primary ways AWS Databrick integrates with other Amazon services.
Connection with Amazon S3 for Data Storage
Databricks on AWS integrates with Amazon S3, AWS’s scalable storage service. This integration allows you to store and retrieve large amounts of data at any time, from anywhere on the web. With this feature, you can use Amazon S3 as a data lake for your big data analytics tasks, providing a scalable, secure, and cost-effective solution for data storage.
Integration with AWS Glue for ETL jobs
Databricks also integrates with AWS Glue, a fully managed ETL service. AWS Glue allows you to easily prepare and load your data for analytics. When used in conjunction with Databricks, it can automate much of the time-consuming data preparation tasks, making it easier to get your data ready for analysis.
Use of Amazon Redshift for Data Warehousing
Databricks on AWS also interfaces with Amazon Redshift, AWS’s fully managed data warehousing service. Amazon Redshift delivers fast querying capabilities over petabyte-scale datasets, making it an excellent choice for large-scale data analytics tasks. With Databricks on AWS, you can leverage the power of Amazon Redshift to handle complex queries and gain insights from your data.
Interfacing with AWS Lambda for Serverless Computing Tasks
Lastly, Databricks on AWS integrates with AWS Lambda, a service that lets you run your code without provisioning or managing servers. AWS Lambda can trigger your code in response to events, such as changes to data in an Amazon S3 bucket. With this integration, you can automate various data processing tasks, making your data pipelines more efficient.
Setting Up Databricks on AWS
Before starting the Quick Start deployment, ensure to have your Databricks E2 account ID.
To deploy Databricks on AWS:
- Log into your AWS account and initiate the AWS Databricks Partner Solution. The AWS CloudFormation interface will appear with a template ready for use.
- Select the appropriate AWS Region, then click Next.
- In the Create stack page, retain the default setting for the template URL and click Next.
- In the Specify stack details page, modify the stack name, if necessary. Review the parameters for the template and fill out those that need an input. For remaining parameters, check the default settings and adjust if required. Click Next.
- Within the Configure stack options page, you can assign tags (key-value pairs) for your stack resources and establish advanced options. Once completed, click Next.
- In the Review page, validate and acknowledge the template settings. Under Capabilities, tick all boxes to confirm that the template should create the necessary AWS Identity and Access Management (IAM) resources.
- Click Create stack. Please note the stack deployment could take around 15 minutes.
- Keep an eye on the stack’s status. On reaching the status CREATE_COMPLETE, the Databricks deployment is all set.
- To inspect the resources created, select the Outputs tab.
Steps after deployment:
- When the status is CREATE_COMPLETE for the AWS CloudFormation stack, confirm the WorkspaceStatus output key value. It should display as RUNNING.
- Go to the workspace URL (e.g., deployment-name.cloud.databricks.com) and log into the web application.
Autonomous Databricks Optimization Solutions
For the next level of optimizing Databricks workloads, there are autonomous, continuous solutions that can improve speed and reduce costs. Granulate continuously and autonomously optimizes large-scale Databricks workloads for improved data processing performance.
With Granulate’s optimization solution, companies can minimize processing costs across Spark workloads in Databricks environments and allow data engineering teams to improve performance and reduce processing time.
By continuously adapting resources and runtime environments to application workload patterns, teams can avoid constant monitoring and benchmarking, tuning workload resource capacity specifically for Databricks workloads.