
What Is Horizontal Pod Autoscaler (HPA)?
A Kubernetes cluster is made up of one or more virtual machines called nodes. In Kubernetes, a pod is the smallest resource in the hierarchy and your application containers are deployed as pods. A pod is a logical construct in Kubernetes and requires a node to run, and a node can have one or more pods running inside of it.
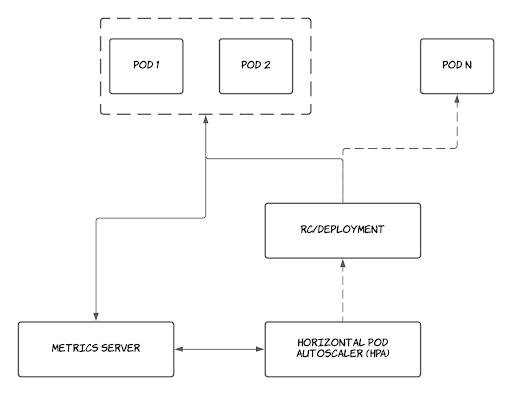
Horizontal Pod Autoscaler is a type of autoscaler that can increase or decrease the number of pods in a Deployment, ReplicationController, StatefulSet, or ReplicaSet, usually in response to CPU utilization patterns. This process represents horizontal scaling because it changes the number of instances, not the resources allocated to a given container.
This is part of a series of articles about kubernetes performance.
In this article:
- How Does HPA Work and What Are Its Benefits?
- Kubernetes Autoscaling Basics: HPA vs. HPA vs. Cluster Autoscaler
- What Is the Impact of HPA on Kubernetes Resource Costs?
- How to Use HPA Metrics
- HPA Example: Scaling a Deployment via CPU and Memory Metrics
- Limitations of Horizontal Pod Autoscaler
- Kubernetes HPA Best Practices
How Does HPA Work and What Are Its Benefits?
By default, HPA scales workloads based on pod metrics like average CPU utilization and average pod utilization. It is also possible to use externally provided or custom metrics. After the initial setup, it can operate automatically – you only need to define the minimum and the maximum number of replicas.
The configured HPA controller is responsible for checking metrics and scaling replicas accordingly by adding or removing pods. This scaling occurs automatically, but you can sometimes account for predictable fluctuations in loading requirements. HPA works in a loop by checking, updating, and re-checking metrics.

In the first step of the HPA loop, the controller continuously tracks resource utilization via the metrics server. Next, HPA calculates the optimal number of replicas based on the resource requirements. Then, the autoscaler decides whether to scale the application up or down. In the last step of the loop, HPA implements the target number of replicas.
HPA is a continuous monitoring process, so this loop repeats as soon as it finishes.
Kubernetes Autoscaling Basics: HPA vs. HPA vs. Cluster Autoscaler
Let’s compare HPA to the two other main autoscaling options available in Kubernetes.
Horizontal Pod Autoscaling
HPA increases or decreases the number of replicas running for each application according to a given number of metric thresholds, as defined by the user.
Vertical Pod Autoscaling
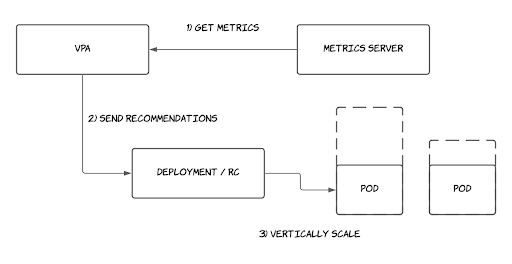
The Vertical Pod Autoscaler (VPA) constantly monitors CPU and memory usage of running applications. It provides recommendations for the ideal number of resources that should be dedicated to a given application and scales the application vertically as needed.
Cluster Autoscaler
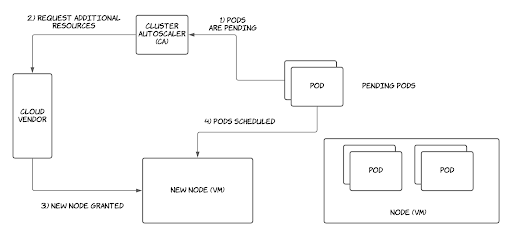
Cluster Autoscaler is a mechanism for scaling Kubernetes resources at the infrastructure level according to a given set of scaling rules. It works by constantly monitoring cluster status, and making infrastructure-level scaling decisions.
In Cluster Autoscaler, infrastructure-level scaling is triggered when one of the following events occur:
- Kubernetes pods go into a pending state in the cluster without being able to be scheduled into a node due to insufficient memory or CPU. This triggers scaling up with new nodes being provisioned.
- Kubernetes nodes are underutilized and the workloads running in those nodes can be safely rescheduled into another existing node. This triggers scaling down and removing provisioned nodes.
What Is the Impact of HPA on Kubernetes Resource Costs?
Running multiple workloads on a server instance can be cost-effective, but tracking your Kubernetes costs and identifying where you can save is challenging. Autoscaling lets you tightly configure scaling to reduce waste and minimize application running costs.
Application usage often changes over time, requiring more or fewer pod replicas. HPA scales your workloads automatically. It is useful for stateless and stateful applications. Combining HPA with cluster scaling helps reduce costs for workloads with frequent demand changes, decreasing the number of nodes alongside the pods.
Properly configured, the HPA controller can monitor pods to determine if the number of replicas needs changing. It compares the current value to the target value.
How to Use HPA Metrics
As discussed above, the Horizontal Pod Autoscaler (HPA) enables horizontal scaling of container workloads running in Kubernetes. In order for HPA to work, the Kubernetes cluster needs to have metrics enabled. See how to enable metrics in the Kubernetes metrics server tool
Kubernetes HPA supports four kinds of metrics:
Resource Metric
Resource metrics refer to CPU and memory utilization of Kubernetes pods against the values provided in the limits and requests of the pod spec. These metrics are natively known to Kubernetes through the metrics server. The values are averaged together before comparing them with the target values. That is, if three replicas are running for your application, the utilization values will be averaged and compared against the CPU and memory requests defined in your deployment spec.
Object Metric
Object metrics describe the information available in a single Kubernetes resource. An example of this would be hits per second for an ingress object.
Pod Metric
Pod metrics (referred to as PodsMetricSource) references pod-based metric information at runtime and can be collected in Kubernetes. An example would be transactions processed per second in a pod. If there are multiple pods for a given PodsMetricSource, the values will be collected and averaged together before being compared against the target threshold values.
External Metrics
External metrics are metrics gathered from sources running outside the scope of a Kubernetes cluster. For example, metrics from Prometheus can be queried for the length of a queue in a cloud messaging service, or QPS from a load balancer running outside of the cluster.
HPA Example: Scaling a Deployment via CPU and Memory Metrics
The following is an example of scaling a deployment by CPU and memory. For CPU, the average utilization of 50% is taken as the target, and for memory, an average usage value of 500 Mi is taken. In addition, there is an object metric that monitors the incoming requests per second in ingress and scales the application accordingly.
apiVersion: autoscaling/v2beta2 kind: HorizontalPodAutoscaler metadata: name: sample-app-hpa namespace: default spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: sample-app minReplicas: 1 maxReplicas: 10 metrics: - type: Resource resource: name: cpu target: type: Utilization averageUtilization: 50 - type: Resource resource: name: memory target: type: AverageValue averageValue: 500Mi - type: Object object: metric: name: requests-per-second describedObject: apiVersion: networking.k8s.io/v1beta1 kind: Ingress name: main-route target: type: Value value: 10k
HPS also enables scaling behavior tuning and a stabilization window. Either a single scaling behavior policy or more than one can be attached to an HPA, and the policy that results in the highest amount of change for a given instance is automatically selected.
behavior: scaleDown: policies: - type: Pods value: 4 periodSeconds: 60 - type: Percent value: 10 periodSeconds: 60
In the above example, if there are 100 replicas running, the HPA will look at the two policies available. The first policy tells the autoscaler to remove 4 pods at a time in a period of 60 seconds. The second policy tells the autoscaler to remove 10% of the current replica number in 60 seconds. The second policy has the highest impact, as it would remove 10 pods in the first 60 second window.
In the next 60 second window, 9 pods (10%) would be removed from the remaining 90. In the third iteration, 9 will be removed again, as 9 is the ceiling value of 81 multiplied by 0.10. When it reaches 40 replicas, the first policy will take over, as the second policy would have a lower impact than 4 pods. Therefore, from 40 pods onward the autoscaler will continually remove 4 pods at each iteration.
The stabilization window is another important configuration that needs to be set with behavior policies. A stabilization window is used to restrict scaling decisions by observing historical data for a designated time period. This keeps the number of replicas constant in the event of fluctuating metrics, which could result in the replica count going up and down in a short period of time.
For example, if a scaling threshold is reached within 60 seconds, then suddenly drops and rises again, the replica count will remain consistent until the stabilization window is reached.
The following snippet shows how to fine-tune the stabilization period.
scaleDown: stabilizationWindowSeconds: 300
The following shows the default values for HPA when it comes to scaling policies. Unless you have specific requirements, you don’t have to change these.
behavior: scaleDown: stabilizationWindowSeconds: 300 policies: - type: Percent value: 100 periodSeconds: 15 scaleUp: stabilizationWindowSeconds: 0 policies: - type: Percent value: 100 periodSeconds: 15 - type: Pods value: 4 periodSeconds: 15 selectPolicy: Max
Limitations of Horizontal Pod Autoscaler
While HPA is most useful for autoscaling a stateless application, it can also work with stateful sets. However, HPA also has some limitations:
- The application architecture must support distributed workloads – you might need to architect the application to support scaling. Otherwise, it might be impossible to distribute workloads across different servers.
- HPA cannot always handle unexpected spikes in demand – new virtual machines can take several minutes to load, making it hard to keep up with sudden changes in demand.
- Pods can waste resources or terminate frequently – if you don’t configure memory and CPU limits on the pods, they might work inefficiently.
- The cluster can run out of capacity – HPA will not be able to increase the number of pods until you add new nodes to your cluster. You can use Cluster Autoscaler (CA) to scale nodes automatically.
Kubernetes HPA Best Practices
When running production workloads with autoscaling enabled, there are a few best practices to keep in mind.
- Install a metric server: Kubernetes requires a metrics server be installed in order for autoscaling to work. The metrics server enables the Kubernetes metric APIs, which the autoscaling algorithms utilize, to make scaling decisions.
- Define pod requests and limits: A Kubernetes scheduler makes scheduling decisions according to the requests and limits set in the pod. If not set properly, Kubernetes will be unable to make an informed scheduling decision, and pods will not go into a pending state due to lack of resources. Instead, they will go into a CrashLoopBackOff, and Cluster Autoscaler won’t kick in to scale the nodes. Furthermore, with HPA, if initial requests are not set to retrieve the current utilization percentages, scaling decisions will not have a proper base to match resource utilization policies as a percentage.
- Specify PodDisruptionBudgets for mission-critical applications: PodDisruptionBudget avoids disruption of critical pods running in the Kubernetes Cluster. When a PodDisruptionBudget is defined for a certain application, autoscaler will avoid scaling down replicas beyond the minimum value configured in the disruption budget.
- Resource requests should be close to the average usage of the pods: Sometimes an appropriate resource request can be hard to determine for new applications, as they have no previous resource utilization data. However, with Vertical Pod Autoscaler, you can easily run it in recommendation mode. Recommendations for the best values for CPU and memory requests for your pods are based on short-term observations of your application’s usage.
- Increase CPU limits for slow starting applications: Some applications (ex: Java Spring) require an initial CPU burst to get the application up and running. At runtime the application would typically use a small amount of CPU compared to the initial load. To mitigate this, it is recommended to limit CPU to a higher level. This will allow these containers to start up quickly and to add lower request levels that match the typical runtime request usage of these applications.
- Don’t mix HPA with VPA: Horizontal Pod Autoscaler and Vertical Pod Autoscaler should not be run together. It is recommended to run Vertical Pod Autoscaler first, to get the proper values for CPU and memory as recommendations, and then to run HPA to handle traffic spikes.