
Kubernetes is used to orchestrate container workloads in scalable infrastructure. While the open-source platform enables customers to respond to user requests quickly and deploy software updates faster and with greater resilience than ever before, there are some performance and cost challenges that come with using K8s.
Imagine a scenario where an application you deploy has more traffic than you had anticipated, and you are struggling with the provisioned compute resources. You can solve this by scaling your infrastructure. If your application has more traffic during the day, and less traffic during night and weekend hours, it doesn’t make sense to underutilize compute resources during off-peak hours. By using autoscaling, you can easily and dynamically provision more compute power when you need it.
However, with the advantages of automation there always comes the risk of inefficiencies. When autoscaling goes into effect, small issues that were acceptable in early stages can become devastating to the bottom line.
Scaling with Kubernetes
Before diving deep into Kubernetes autoscaling, it’s important to understand two key Kubernetes concepts: nodes and pods. A Kubernetes cluster is made up of one or more virtual machines called nodes. In Kubernetes, a pod is the smallest resource in the hierarchy and your application containers are deployed as pods. A pod is a logical construct in Kubernetes and requires a node to run, and a node can have one or more pods running inside of it. An overview of nodes and pods is available on the Kubernetes website.
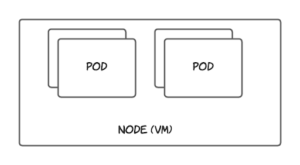
There are three main autoscaling options available in Kubernetes. They are as follows:
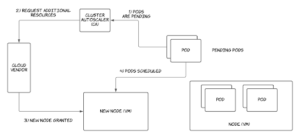
- Cluster autoscaling: This refers to scaling Kubernetes resources at the infrastructure level according to a given set of scaling rules. This is implemented by deploying Cluster Autoscaler—a standalone application that runs in the cluster—constantly monitoring cluster status, and making infrastructure-level scaling decisions. With the pay-as-you-go model implemented in cloud computing, cluster autoscaling has become widely popular due to its efficiency. In Cluster Autoscaler, infrastructure-level scaling is triggered when one of the following events occur.
- Kubernetes pods go into a pending state in the cluster without being able to be scheduled into a node due to insufficient memory or CPU. This triggers scaling up with new nodes being provisioned.
- Kubernetes nodes are underutilized and the workloads running in those nodes can be safely rescheduled into another existing node. This triggers scaling down and removing provisioned nodes.
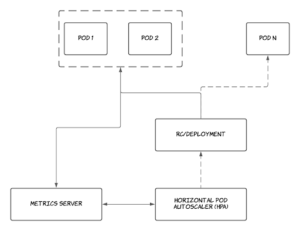
- Horizontal pod autoscaling: The Horizontal Pod Autoscaler is responsible for scaling containers running as pods horizontally in the Kubernetes cluster. It increases or decreases the number of replicas running for each application according to a given number of metric thresholds, as defined by the user.
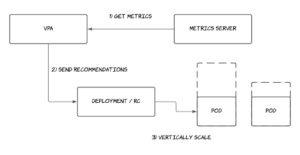
- Vertical pod autoscaling: The Vertical Pod Autoscaler (VPA) constantly monitors CPU and memory usage of running applications. It provides recommendations for the ideal number of resources that should be dedicated to a given application and scales the application vertically as needed.
How Horizontal Pod Autoscaler Works
As discussed above, the Horizontal Pod Autoscaler (HPA) enables horizontal scaling of container workloads running in Kubernetes. In order for HPA to work, the Kubernetes cluster needs to have metrics enabled. Metrics can be enabled by following the installation guide in the Kubernetes metrics server tool available at GitHub. At the time this article was written, both a stable and a beta version of HPA are shipped with Kubernetes. These versions include:
- Autoscaling/v1: This is the stable version available with most clusters. It only supports scaling by monitoring CPU usage against given CPU thresholds.
- Autoscaling/v2beta1: This beta version supports both CPU and memory thresholds for scaling. This has been deprecated in Kubernetes version 1.19.
- Autoscaling/v2beta2: This is the beta version that supports CPU, memory, and external metric thresholds for scaling. This is the recommended API to use if you need autoscaling support for metrics other than CPU utilization.
The remainder of this article will focus on Autoscaling/v2beta2, the latest version of the HPA. HPA allows users to set different metric thresholds to manipulate scaling pods in Kubernetes. Kubernetes HPA supports four kinds of metrics as described below.
Resource Metric
Resource metrics refer to CPU and memory utilization of Kubernetes pods against the values provided in the limits and requests of the pod spec. These metrics are natively known to Kubernetes through the metrics server. The values are averaged together before comparing them with the target values. That is, if three replicas are running for your application, the utilization values will be averaged and compared against the CPU and memory requests defined in your deployment spec.
Object Metric
Object metrics describe the information available in a single Kubernetes resource. An example of this would be hits per second for an ingress object.
Pod Metric
Pod metrics (referred to as PodsMetricSource) references pod-based metric information at runtime and can be collected in Kubernetes. An example would be transactions processed per second in a pod. If there are multiple pods for a given PodsMetricSource, the values will be collected and averaged together before being compared against the target threshold values.

Best Practices
When running production workloads with autoscaling enabled, there are a few best practices to keep in mind.
- Install a metric server: Kubernetes requires a metrics server be installed in order for autoscaling to work. The metrics server enables the Kubernetes metric APIs, which the autoscaling algorithms utilize, to make scaling decisions.
- Define pod requests and limits: A Kubernetes scheduler makes scheduling decisions according to the requests and limits set in the pod. If not set properly, Kubernetes will be unable to make an informed scheduling decision, and pods will not go into a pending state due to lack of resources. Instead, they will go into a CrashLoopBackOff, and Cluster Autoscaler won’t kick in to scale the nodes. Furthermore, with HPA, if initial requests are not set to retrieve the current utilization percentages, scaling decisions will not have a proper base to match resource utilization policies as a percentage.
- Specify PodDisruptionBudgets for mission-critical applications: PodDisruptionBudget avoids disruption of critical pods running in the Kubernetes Cluster. When a PodDisruptionBudget is defined for a certain application, autoscaler will avoid scaling down replicas beyond the minimum value configured in the disruption budget.
- Resource requests should be close to the average usage of the pods: Sometimes an appropriate resource request can be hard to determine for new applications, as they have no previous resource utilization data. However, with Vertical Pod Autoscaler, you can easily run it in recommendation mode. Recommendations for the best values for CPU and memory requests for your pods are based on short-term observations of your application’s usage.
- Increase CPU limits for slow starting applications: Some applications (ex: Java Spring) require an initial CPU burst to get the application up and running. At runtime the application would typically use a small amount of CPU compared to the initial load. To mitigate this, it is recommended to limit CPU to a higher level. This will allow these containers to start up quickly and to add lower request levels that match the typical runtime request usage of these applications.
- Don’t mix HPA with VPA: Horizontal Pod Autoscaler and Vertical Pod Autoscaler should not be run together. It is recommended to run Vertical Pod Autoscaler first, to get the proper values for CPU and memory as recommendations, and then to run HPA to handle traffic spikes.
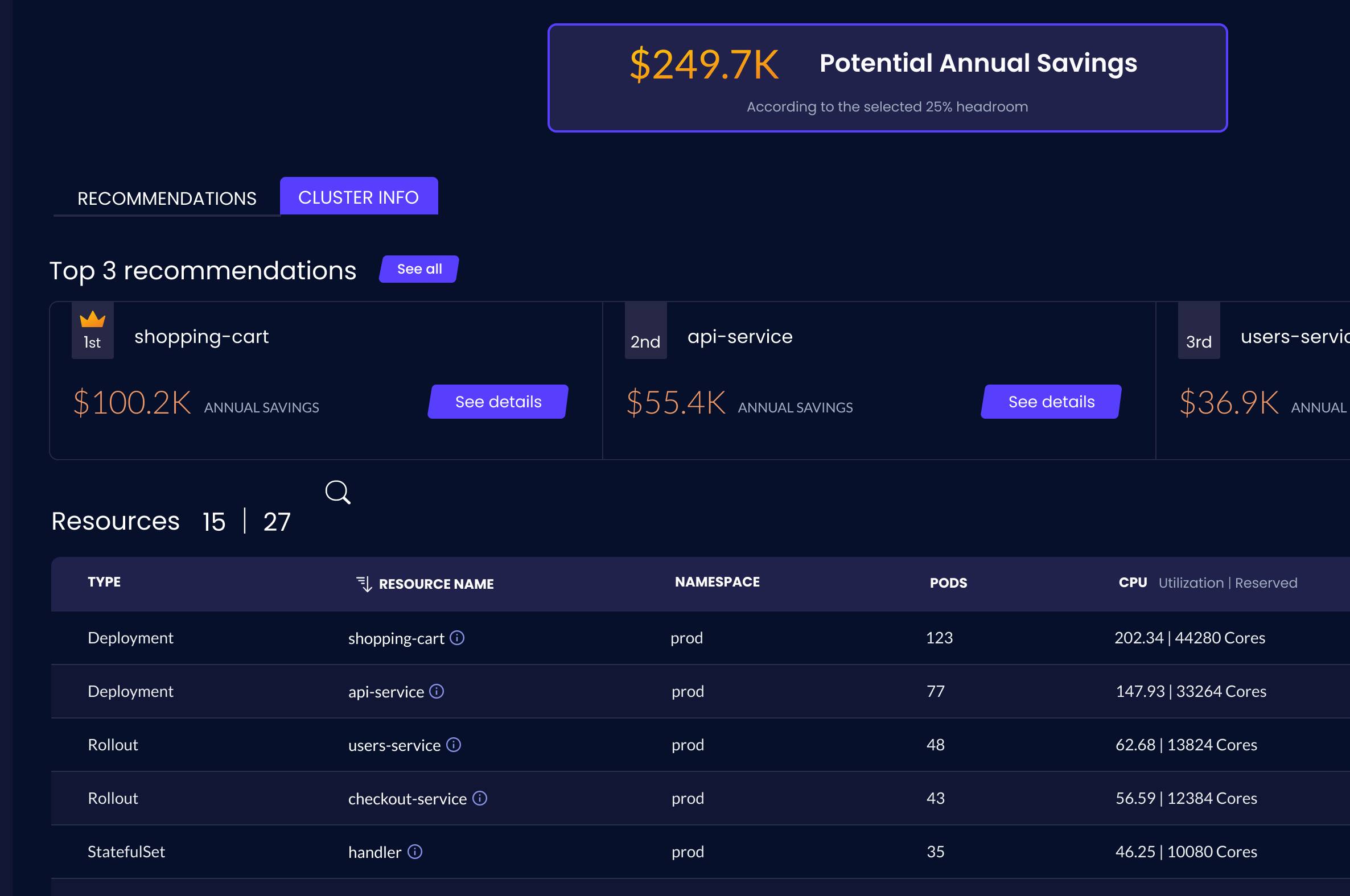
- Implement a 3rd-party optimization solution: There are different solutions in the market today that enable organizations to overcome performance and cost challenges when it comes to K8s, such as over-provisioning and HPA/VPA limitations (mentioned above). Granulate’s Capacity Optimizer, for example, leverages autonomous workload and pod rightsizing so you pay only for what you use while maintaining optimal performance to ensure competitive SLAs remain the same.
Conclusion
Kubernetes have played a key role in managing containerized environments and reducing development times, yet cost and resource management remain a challenge. The costs of over-provisioning, as well as mismanaged and idle resources have climbed and become a major financial burden for companies globally.
The Horizontal Pod Autoscaler is the most widely used and stable version available in Kubernetes for horizontally scaling workloads. However, this may not be suitable for every type of workload. HPA works best when combined with Cluster Autoscaler to get your compute resources scaled in tandem with the pods within the cluster. In fact, by using both vertical and horizontal scaling, companies can maximize their cost optimization. These guidelines and insights can help you optimize your resources as you begin your journey with autoscaling on Kubernetes.
Learn more in our detailed guide to Kubernetes hpa best practices