
Apache Kafka, a distributed messaging system maintained by the Apache Software Foundation, has become the default choice for inter-service communication in most modern use cases. Kafka facilitates parallel processing of messages and is one of the best tools for inter-process communication in a distributed system, with features such as consumer groups and topic partitions.
However, especially when scaling messages, you need to analyze the performance of Kafka and keep tuning it to make sure latency remains low and throughput high for optimal performance.
Components of a Kafka cluster
There are three major components of Apache Kafka: producers, consumers, and brokers. Understanding their functions will help you optimize Kafka’s performance.
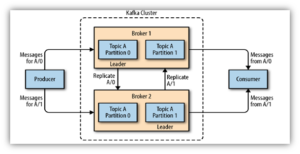
Apache Kafka Architecture and Components (Source: Medium)
Producers
Producers connect to a Kafka cluster either via Zookeeper or directly to a Kafka broker. Once connected, they can specify the topic and partition (a topic can have several) to which a message has to be published. If the partition is not explicitly mentioned by the producer, Kafka will decide that implicitly.
Consumers
Consumers can specify both the topic and partition from which they want to receive messages. If consumers don’t specify the partition, Kafka will decide and can choose more than one, depending on the number of partitions available. A topic, however, cannot have more consumers than partitions.
Similarly, if multiple services want to consume the same message but perform different actions on that data (for example, logging and aggregating metrics), services can consume messages from different consumer groups; each consumer group will get the same message.
Brokers
A Kafka broker serves as a mediator between the producers and consumers by hosting the topics and partitions and facilitating the sending and receiving of messages. Kafka uses Zookeeper to manage brokers.
In a typical production Kafka cluster, there are multiple brokers, each capable of thousands of reads and writes a second. Producers and consumers connect to these brokers, not to each other directly. This ensures that even if a producer or a consumer goes down, the messaging pipeline is not affected.
Kafka Main Performance Metrics
Even though Kafka is already optimized out of the box, there is some tuning you can do to improve cluster performance. When doing so, there are two main metrics to consider:
- Throughput: the number of messages that arrive in a given amount of time
- Latency: the amount of time it takes to process each message
Most systems focus on optimizing one or the other, but Kafka seeks to optimize both.
Latency depends mostly on the business logic you apply for processing each message, so optimizing it involves tuning that logic. But the throughput of the cluster depends on the cluster itself, and this is where having multiple brokers can help. As the number of messages being published increases, you’ll also have to scale up brokers, storage, and consumers to prevent bottlenecks.
High latency in the data pipeline will lead to a huge lag in the consumption of messages. If there aren’t enough brokers to achieve the required throughput, requests from producers to brokers will time out, leading to message loss. This could become a major pain point for your business, so balancing throughput and latency in a Kafka cluster is very important.
Kafka Performance Tuning
Optimizing the performance of a Kafka cluster involves tuning all three components to achieve the desired throughput and latency.
Tuning Brokers
You control the number of partitions in a topic. Increasing the number of partitions and the number of brokers in a cluster will lead to increased parallelism of message consumption, which in turn improves the throughput of a Kafka cluster; however, the time required to replicate data across replica sets will also increase.
Tuning Producers
You can run a producer in two different modes: synchronous and asynchronous. In synchronous mode, as soon as a message is published, the producer sends a request to the broker. So if you’re producing 100 messages a second, the producer will send out 100 requests a second to the broker; this decreases throughput and acts as a blocking operation. So when publishing a high number of messages, it’s better to run producers in asynchronous mode.
But even in asynchronous mode, you need to tune two parameters for optimal performance: batch.size and linger.ms (linger time). Batch size is the size of data to be sent in one batch, measured in bytes. For example, if you set this to 100, the producer will wait until messages add up to 100 bytes before making a call to the broker. If message production is low and you set a high batch size, the producer is going to wait a long time before eventually producing messages. This will not only reduce throughput but also increase message-delivery latency. So depending on the number of messages being produced, this value has to be optimized. The default batch size is 16,384.
Linger time is another metric based on which a producer decides when to send a request to a broker. Using the previous example, if the batch size is set to 100 bytes and you’re only producing 50 bytes a second, the producer will have to wait two seconds before publishing those messages. To avoid this delay, you can tune the linger time (measured in milliseconds) to make sure that the producer doesn’t wait too long before sending out messages. So, setting the linger time to 500 ms in the example above will make the producer wait only half a second at most.
Compression can also improve latency. By default, Kafka messages are not compressed, but you can configure producers to compress them. Brokers and consumers will then have the added overhead of decompressing them, but the overall latency should be reduced as the physical size of data transmitted over the network is smaller.
Tuning Consumers
Consumers receive messages in batches, similar to how producers publish in batches. If you pull a large number of messages and take a lot of time to process each one, the throughput is going to suffer. Similarly, if you poll the broker for a single message every time, the number of requests to the broker may decrease throughput.
As previously discussed, having more partitions and consumers within a consumer group can help improve throughput. But keep in mind that as the number of consumers increases, the number of offset commit requests to the broker will also increase. And because committing an offset is basically sending a Kafka message to an internal topic, this will increase the load on the broker indirectly. So having an optimal number of consumers is crucial.
MirrorMaker Performance Optimization
Kafka MirrorMaker is a tool used to mirror Kafka messages from one data center or cluster to another. Because this is internally just producing messages to Kafka, most optimization techniques already discussed hold true here as well. But since this also involves transmitting messages over long distances, there are a few more configuration parameters that can be tuned for better performance. Note: When tuning, make sure to base your actions on the needs of your particular business use case.
MirrorMaker Location
MirrorMaker can be installed either at the source or the destination. Installing at the destination is better because producing messages over long distances increases the chances of losing data during transmission.
Compression
By default, message compression in Kafka producers is set to none. You can change this to gzip to compress messages going out from the source to the destination, which helps with larger batch sizes.
Batch Size
Increasing the batch size of messages increases throughput, and combining this with compression makes sure that a large number of messages are being transmitted quickly. If the target batch size is taking more time than the linger time configured, it means that the batches being sent out are not completely filled. This not only decreases compression efficiency but also wastes bandwidth. So tuning batch size along with enabling compression and tuning linger time is important.
Linger Time
As discussed earlier, increasing linger time to allow batches to be filled completely is important. This might increase latency a bit, but overall throughput will improve. So you need to take into consideration how important latency is for your given business use case.
Increase Parallelism
To increase throughput further, you can deploy multiple instances of MIrrorMaker under the same consumer group. This will facilitate multiple MirrorMaker consumers receiving from the same source and producing to the destination in parallel.
Production Server Configurations in Kafka Tuning
There are a few other configuration parameters you can tune to improve the performance of Kafka in a production environment. These parameters also improve the replication performance of messages within partitions:
- num.replica.fetchers specifies the number of threads used to replicate messages from the leader to the followers; a higher number of replica fetchers improves parallelism in replication.
- replica.fetch.max.bytes indicates the number of bytes of data to fetch from the leader; a larger number here indicates a larger chunk of data being fetched, improving the throughput of replication.
- num.partitions specifies the maximum number of consumers a topic can have in a given user group, which is equal to the number of partitions available in that topic; so increasing the partitions increases parallelism and therefore throughput. However, a large number of partitions will also consume more resources, so you’ll have to scale up resources as well.
Balancing Apache Kafka Clusters
Whenever a new broker is added to a Kafka cluster, existing partitions are not distributed via the new broker. That means the new broker is not doing much, and if one or more old brokers go down, replication and potential leaders are reduced. This is known as leader skew. You can avoid this by making sure any newly added broker gets a share of the partitions—rebalancing the cluster is important. Similarly, if a broker has more than the average number of partitions for a topic, known as broker skew, it can lead to performance issues.
Solving these balancing or skewing issues is as simple as running one or two shell scripts that ship with Kafka. For example, to solve a leader skew, you can run the kafka-preferred-replica-election.sh shell script or set auto.leader.rebalance.enable to “true.” And to solve a broker skew, run the kafka-reassign-partition.sh script to get the proposed reassignment plan. Copy that plan to a JSON file and run it to apply the new plan. Then run the kafka-preferred-replica-election.sh script to finalize the rebalancing.
Optimizing Kafka Performance
When you’re running Kafka as a cluster, there are multiple ways to optimize its performance. You can tune various configuration parameters to strike a balance between throughput and latency. There is also a fair amount of engineering involved to calculate the optimal values for some of these parameters, such as linger time, batch size, number of partitions, etc. Depending on your given use case, you may decide that throughput is more important than latency, or vice versa, or that a balance between the two is best.